Martín Alejandro Castro Álvarez
Software Engineer
martincastro.10.5@gmail.comhttps://martincastroalvarez.comhttps://github.com/MartinCastroAlvarezhttps://www.linkedin.com/in/martincastroalvarez/Martín Alejandro Castro Álvarez, Software Engineer
martincastro.10.5@gmail.com
https://martincastroalvarez.com
https://github.com/MartinCastroAlvarez
https://www.linkedin.com/in/martincastroalvarez/
I am an experienced software engineer with a passion for building scalable, AI-powered solutions. My proven track record includes leading cross-functional teams and delivering production-grade systems across multiple industries.
I specialize in full-stack development, cloud infrastructure, and machine learning. My strong background includes Python, JavaScript, and modern web technologies.
I have extensive experience leading technical teams and architecting production systems across AI, cloud infrastructure, and full-stack development domains.
I am a good fit because I combine technical expertise with leadership experience, enabling me to deliver scalable solutions while mentoring teams and driving technical excellence.
I am an experienced software engineer with a passion for building scalable, AI-powered solutions. My proven track record includes leading cross-functional teams and delivering production-grade systems across multiple industries.
I specialize in full-stack development, cloud infrastructure, and machine learning. My strong background includes Python, JavaScript, and modern web technologies.
I have extensive experience leading technical teams and architecting production systems across AI, cloud infrastructure, and full-stack development domains.
I am a good fit because I combine technical expertise with leadership experience, enabling me to deliver scalable solutions while mentoring teams and driving technical excellence.
Skills
Team Leadership
MentoringProduct DesignCode ReviewCross-functionalRoadmappingTechnical DecisionsTeam ProductivityConflictArchitecture Design
System ArchitectureMicroservicesEvent-DrivenData PipelinesMicrofrontendsDistributed SystemsAPI DesignScalabilityBackend
DjangoNodeRustFastAPIFlaskPythonWarpJavaFrontend
ReactGraphQLVueJSMicrofrontendsNodeReduxSvelteAngularTypeScriptWeb3
SolidityRustEthereumweb3.jsethers.jsAlchemyIPFSMetaMaskFoundryAnvilSmart ContractsNFTsOpenZeppelinData Engineering
Streaming de datosSparkCassandraNoSQLRedshiftBigQueryAWS RDSAWS S3LookerTableauAWS ElastiCacheKafkaETLSQLAWS DynamoDBElasticsearchSnowflakeAWS KinesisGoogle Cloud SQLGoogle Cloud StorageMetabaseAmazon NeptuneAWS AthenaDevOps
DockerLinuxVPCAWS CDKAnsibleCloud MonitoringAWS API GatewayRabbitMQCeleryGitLab CIAWS CodePipelineKubernetesAWS CloudWatchTerraformPulumiShellAWS LambdaGoogle Pub/SubAWS SQSGitHub ActionsCircleCIAI
LangChainOpenAI Agent SDKPyTorchPandasRAGSpaCyOpenCVGoogle ADKNumPyKerasTensorFlowEmbeddingsGensimStreamlitTesting
jestpytestbehaveplaywrightseleniumvitestunittestlocustcypressLanguages
SpanishEnglish2024 - Today · AI Tech Lead · Laminr
San Francisco, US
Laminr is an innovative AI company specializing in developing advanced agent-based solutions to automate complex business processes and workflows.
I established a comprehensive mentorship program focused on knowledge transfer to engineering team members, translating complex business requirements into executable technical tasks. I conducted regular educational meetings, live-coding sessions, pair-programming workshops, and coding bootcamps to foster team collaboration and accelerate skill development across the organization.
I architected and shipped a production fleet of autonomous AI agents (agentic AI) for financial services, built on the Google Agent Development Kit (ADK) and Vertex AI. I designed and delivered a multi-agent system of named, Slack-resident teammates — a project manager (Scotty), a customer-support agent (Uhura), a release engineer (James), a DevOps / technical-support agent (Geordi), a QA / testing agent (Tuvok), and a software-engineering agent (Wesley) — each a standalone FastAPI service deployed independently on Cloud Run so a bug in one can never take the others down. Every agent shares the same architecture: an ADK root agent composed from a Role + Soul prompt pair, specialized sub-agents (planner, messenger, manager, documenter, validator) for orchestration, and tool calling / function calling over the Model Context Protocol (MCP) against Slack, Shortcut, Outline, GitHub, Sentry, Cloud Run, Datadog, and the Laminr tenant API.
I designed the fleet's shared "teammate" behaviors so the agents operate as a team rather than as isolated bots. I built a markdown-based agent skills system (one skill per file, loaded at build time into the root instruction) covering attention, prioritization, estimation, and role-specific playbooks; a hub-and-spoke escalation model where every spoke knows only that Scotty is its PM and Scotty alone holds the roster; a daily collaborative standup and a #deepmind collaboration channel where agents recruit each other for help; and cron-fired scheduled activities (Cloud Scheduler → /internal/ask with stable per-activity session ids) for standups, pre-release summaries, production monitoring, and twice-daily ops sweeps. I drove the architectural decision to migrate "classify-and-decide" sub-agents into skills to cut an LLM hop, token cost, and a failure surface per turn.
I engineered the agent memory management architecture: a two-tier design with per-conversation session memory and a shared, organization-wide long-term memory backed by Vertex AI Memory Bank, so every agent accumulates company knowledge across all conversations. I implemented semantic memory recall with Retrieval-Augmented Generation (RAG), embeddings, and vector search, plus context engineering (session-key design, full-thread context loading) that eliminated lost-context failures across Slack DMs, threads, and channels.
I designed the agent authorization and safety layer with human-in-the-loop (HITL) controls: AI agents drive high-stakes workflows (production deploys, release PRs) to a merge-ready state while final approval stays human-gated behind explicit feature flags and approval gates. I enforced least-privilege tool surfaces per agent, user allowlists evaluated before any LLM call, idempotent send-path deduplication, and prompt-plus-code defense-in-depth response policies — AI guardrails enforced by the tooling layer, not the model.
I built hallucination protection into every agent: a read-only validator sub-agent acts as an anti-hallucination gate, verifying that every entity named in a draft reply (tickets, documents, services, releases, packages) actually exists against this turn's tool-call journal and live APIs before the reply is sent. I combined this grounding layer with LLM evaluation pipelines, prompt engineering standards, and LLMOps practices for tracing, regression-testing, and monitoring agent behavior in production.
I engineered the agents' memory and context layer on Vertex AI Memory Bank: a two-tier design with per-conversation session memory and a shared, organization-wide long-term bucket, plus per-member long-term buckets so each agent adapts its behaviour to whoever it is talking to. I implemented semantic recall with Retrieval-Augmented Generation (RAG), embeddings, and vector search, and solved two production-grade context bugs — binding per-turn Slack origin in a session-id-keyed store (ContextVar values do not survive ADK's task/thread boundary) and treating the GCS session pointer as a recoverable cache by stamping the Slack surface key into Vertex session state and healing the pointer on a lookup miss.
I built the agents' authorization, ingress, and reliability layer that lets the fleet talk to each other but to nothing else. I implemented a layered Slack ingress gate (self-drop, sibling-bot allowlist, channel allowlist, and an @laminr.ai DM email-domain gate) that runs before the LLM is ever loaded, a narrow response policy so the bots never barge into deploy threads or side conversations, and send-path deduplication (SHA-256 fingerprint over channel/thread/text, backed by GCS, fail-open) so an LLM retry or redelivered Slack event can never post the same message twice. I added a code-side single-fire guard that caches a gate sub-agent's verdict and short-circuits repeat invocations to stop runaway LLM loops.
I developed Computer Vision and document AI capabilities for automated financial document processing, with end-to-end pipelines for image-to-text data extraction (OCR) using state-of-the-art models, and integrated multi-modal AI systems with business workflows for seamless automation.
I led the design and deployment of the platform's Python backend on Django 5: I built REST APIs with Django REST Framework (DRF) and JWT authentication, asynchronous background processing with Celery workers and scheduled tasks over Redis, and a PostgreSQL data layer with Pydantic-validated domain models. I extended the Django Admin for internal operations and connected business intelligence dashboards (Metabase) directly to the Django data model to drive operational insights.
I architected and implemented modern, responsive web applications using React Workspaces with PNPM monorepo setup, Zustand for state management, and React Query for efficient data fetching. I leveraged TypeScript for type safety and Tailwind CSS for rapid UI development, ensuring maintainable and scalable frontend architecture across multiple packages.
I architected and implemented cloud-native infrastructure using Pulumi for IaC, deploying services on GCP (Cloud Run, GKE, Cloud SQL, Memorystore Redis) with zero-downtime deployments. I orchestrated containerized applications on Google Kubernetes Engine (GKE) — Google Cloud's managed Kubernetes service that automates cluster provisioning, autoscaling, upgrades, and security patching — using it to run scalable microservices with horizontal pod autoscaling, node auto-provisioning, workload identity for secure GCP access, and rolling deployments across multi-zone clusters. I established CI/CD pipelines and infrastructure automation for seamless deployments and scaling.
I built a comprehensive QA framework with Playwright for E2E testing and integrated monitoring solutions (Datadog, Sentry) for real-time observability and incident response. I implemented automated testing pipelines and established monitoring best practices for production systems.
I turned ‘what could go wrong’ concerns into concrete mitigations (tests, monitoring, rollout plans), reducing incidents while maintaining shipping cadence.
I shipped a six-agent production fleet of autonomous Slack teammates — a project manager (Scotty), a customer-support agent (Uhura), a release engineer (James), a DevOps / technical-support agent (Geordi), a QA / testing agent (Tuvok), and a software-engineering agent (Wesley) — each deployed as an independent Cloud Run service on Google ADK and Vertex AI.
I built the customer-support agent (Uhura) on the Laminr tenant API, fielding loan-package, eligibility, conformance, and income questions in Slack and human-gating high-stakes reprocessing behind cryptographic Approve/Dismiss authorization.
I built the release-manager agent (James) that drives the main → prod deploy end-to-end — gate checks, release-PR open/review, GitHub Actions monitoring, and real-time #prod-deploy updates — leaving only the human-authorized merge click behind an Approve/Dismiss gate.
I built the project-manager agent (Scotty) as the fleet's hub: planning and scoping, team coordination, the daily collaborative standup, capability-gap tracking, and Shortcut / Outline documentation hand-offs, holding the only roster the other agents escalate to.
I built the DevOps / technical-support agent (Geordi) over Sentry, Cloud Run / Cloud Logging, Cloud Run Jobs, and Datadog, triaging production-error and monitor alerts in-thread and running twice-daily silent-by-default ops sweeps that page humans only when production is bleeding.
I achieved a 40% reduction in onboarding time for new engineers and increased team velocity by 25% within 6 months through structured knowledge transfer.
I reduced document processing time by 80% (from 5 minutes to 1 minute per document) and increased automation coverage from 30% to 85% of business workflows within 4 months.
I increased API response time by 60% (from 500ms to 200ms average) and reduced infrastructure costs by 35% through optimized database queries and caching strategies.
I reduced bundle size by 45% and improved page load time by 50% (from 3.2s to 1.6s) through code splitting and lazy loading optimizations.
I achieved 99.9% uptime and reduced deployment time from 45 minutes to 8 minutes (82% reduction) through automated CI/CD pipelines and infrastructure as code.
I reduced production incidents by 70% and decreased mean time to resolution (MTTR) from 4 hours to 45 minutes through comprehensive test coverage and proactive monitoring.
Tech Stack: Product Requirements, Technical Leadership, Mentorship, Architecture Design, Agentic AI, AI Agents, Multi-Agent Systems, LLM Agents, Google ADK, Vertex AI, MCP, Agent Orchestration, FastAPI, Cloud Run, Agent Skills, Multi-Agent Collaboration, Hub-and-Spoke, Escalation Routing, Scheduled Agents, Cloud Scheduler, Sub-Agent Design, Prompt Engineering, LLM Memory, Long-Term Memory, RAG, Embeddings, Vector Search, Context Engineering, Vertex AI Memory Bank, Semantic Search, Human-in-the-Loop (HITL), AI Guardrails, AI Safety, Responsible AI, AI Governance, Access Control, Least Privilege, Hallucination Detection, AI Grounding, LLM Evaluation, Prompt Engineering, LLMOps, AI Reliability, Trustworthy AI, Vertex AI Memory Bank, Long-Term Memory, Per-Member Memory, RAG, Embeddings, Vector Search, Context Engineering, Session Management, Access Control, Allowlists, Idempotency, Deduplication, AI Guardrails, Defense in Depth, Slack API, Rate Limiting, Computer Vision, OCR, Document AI, LangChain, PyTorch, TensorFlow, Python, Django, Django REST Framework, Celery, PostgreSQL, Redis, Pydantic, Metabase, React, PNPM, Monorepo, Zustand, React Query, Axios, TypeScript, Tailwind, Pulumi, Cloud Run, GKE, Kubernetes, Cloud SQL, Redis, Google Cloud Monitoring, CI/CD, Infrastructure as Code (IaC), Google Cloud Platform (GCP), Playwright, Sentry, Datadog, E2E, Cloud Monitoring, Automated Tests
2022 - 2024 · Blockchain Engineer · Makersplace
San Francisco, US
MakersPlace is a digital creation platform powered by blockchain, enabling creators to sell unique digital artwork.
I built end-to-end digital asset infrastructure integrating Django backends with Solidity smart contracts and Rust-based logic for Web3 protocols. I led NFT and phygital asset deployments using web3.js, Alchemy, and IPFS, integrating smart contracts with full-stack applications. I partnered with cross-functional teams (marketing, sales) to launch blockchain-based digital campaigns that increased user engagement and retention.
I diagnosed and resolved critical failures in blockchain workflows, including transaction validation, IPFS metadata syncing, and dynamic gas optimization. I designed fault-tolerant microservices for real-time blockchain transaction monitoring and distributed data pipelines.
I developed production-grade MLOps pipeline on AWS for scalable model lifecycle management, leveraging Docker, Kubernetes, and SageMaker. I enabled model versioning and continuous monitoring for production ML workflows, ensuring data drift detection and model rollback.
I automated deployment infrastructure using AWS CDK and CI/CD pipelines (GitHub Actions, Elastic Beanstalk, ECR), achieving zero-downtime rollouts. I dockerized applications and managed deployment environments using Elastic Beanstalk, ECR, RDS, and Opensearch.
I directed enterprise-scale data migration to GCP BigQuery, optimizing ETL pipelines with Data Fusion for low-latency analytics. I enabled real-time data access for business intelligence.
I built full-spectrum test automation suite with Cypress, PyTest, and integration testing frameworks — enforced zero-regression policies pre-launch. I validated digital drops and NFT-related product features to ensure high quality and zero regression.
I delivered under aggressive launch timelines by making explicit tradeoffs (guardrails, rollback plans, monitoring) that protected reliability while meeting drop deadlines.
I partnered cross-functionally (marketing/sales + engineering) to ship blockchain features fast, while keeping transaction integrity high through automation and fault-tolerant services.
I increased transaction success rate from 85% to 98% and reduced gas costs by 40% through optimized smart contract design and dynamic gas pricing strategies.
I reduced system downtime by 90% (from 2% to 0.2% monthly) and improved transaction processing throughput by 3x through fault-tolerant architecture and optimized data pipelines.
I reduced model deployment time from 2 weeks to 2 days (90% reduction) and improved model accuracy monitoring coverage from 40% to 95% through automated MLOps pipelines.
I achieved 100% zero-downtime deployments and reduced infrastructure provisioning time from 4 hours to 15 minutes (94% reduction) through infrastructure as code and automated CI/CD.
I reduced data processing latency by 75% (from 4 hours to 1 hour) and decreased data warehouse costs by 50% through optimized ETL pipelines and query optimization.
I increased test coverage from 45% to 92% and reduced regression bugs in production by 85% through comprehensive automated testing.
Tech Stack: web3.js, ethers.js, Alchemy, Moralis, Ethereum, Etherscan, IPFS, Solidity, Rust, MetaMask, Coinbase, Wallet Connect, Solscan, Royalty Registry, Python, Django, Celery, Unit Tests, Airflow, AWS SageMaker, TensorFlow, MLOps, gRPC, Docker, Kubernetes, AWS CDK, AWS Elastic Beanstalk, AWS ECR, AWS RDS, AWS Opensearch, AWS Elasticache, AWS S3, AWS Cloudfront, AWS DMS, BigQuery, Data Fusion, Data Streams, Cypress, Unit Tests, Integration Tests, Functional Tests
2020 - 2022 · Data Engineer · Rings AI
San Francisco, US
An AI-powered platform for opportunity intelligence through relationship data.
I architected and developed a custom CRM platform designed to improve outreach effectiveness using AI-driven insights from network relationship data. I implemented intelligent dataset enrichment by integrating multiple external data sources, enabling personalized outreach strategies and opportunity intelligence. I built machine learning models to analyze relationship patterns and predict optimal engagement approaches. I integrated computer vision capabilities for automated profile image analysis and document processing to enhance contact data quality.
I built real-time distributed graph algorithm in Spark for relationship path analysis. I streamlined data materialization using AWS Glue, SQS, and ETL processes.
I designed high-throughput serverless backend using AWS Lambda, event-driven SQS/SNS queues, and Elasticsearch for log indexing and traceability. I ensured high availability and scalability across the architecture.
I constructed scalable ETL pipelines using AWS Glue and Athena to support Redshift-based data warehousing and interactive querying. I improved data warehouse performance and reporting efficiency.
I optimized cloud network infrastructure with custom VPC architectures, reducing inter-zone data transfer costs by 30% via NAT gateway tuning. I reduced data transfer costs while ensuring security.
I integrated secure authentication and audit logging using AWS Cognito, Google OAuth 2.0, and serverless event-driven Lambda functions. I ensured compliance and traceability.
I implemented micro-frontends in React with GraphQL over AWS AppSync to support real-time UI rendering and scalable user data interactions. I integrated robust data flows using Node and TypeScript.
I created automated QA pipelines with Cypress, GitHub Actions, and Slack alerts to ensure continuous delivery and rapid feedback loops. I managed CI/CD workflows to maintain code quality.
I performed production diagnostics using AWS observability stack (CloudWatch, X-Ray, custom metrics), producing detailed RCA reports. I delivered actionable RCA reports and fixes.
I worked in Agile teams using Scrum, Jira, and Confluence. I optimized sprint velocity and stakeholder communication.
I built probabilistic matching algorithms using AWS Glue and distributed lookups. I enhanced data integration across sources.
I deployed secure CDN with Lambda@Edge and CloudFront. I reduced latency and improved user content delivery.
I applied cost tags and managed resources with AWS Organizations. I enhanced budget accountability and forecast accuracy.
I collaborated effectively with very direct, high-bar engineers by focusing on evidence: benchmarks, RFCs, and reproducible experiments—turning sharp debate into better architecture.
I navigated high-stakes stakeholder pressure by documenting tradeoffs, defining objective success metrics, and protecting delivery from last-minute churn.
I increased outreach conversion rates by 65% and reduced data enrichment time from 2 hours to 15 minutes per contact through AI-powered automation.
I reduced graph computation time by 70% (from 30 minutes to 9 minutes) and improved data accuracy from 78% to 95% through optimized graph algorithms and real-time processing.
I achieved 99.95% uptime and reduced infrastructure costs by 60% compared to traditional EC2-based architecture while handling 10x traffic spikes.
I reduced ETL processing time by 55% (from 6 hours to 2.7 hours) and decreased query latency by 40% through optimized data partitioning and columnar storage strategies.
I achieved 30% cost reduction in data transfer costs ($15K to $10.5K monthly) and improved network latency by 25% through optimized VPC architecture and NAT gateway configuration.
I reduced authentication failures by 80% and achieved 100% audit trail coverage for all user actions, ensuring full compliance with security requirements.
I reduced API response time by 50% (from 400ms to 200ms) and decreased frontend bundle size by 35% through GraphQL query optimization and code splitting.
I increased test automation coverage from 30% to 88% and reduced time-to-feedback from 2 days to 2 hours through automated CI/CD pipelines.
I reduced mean time to resolution (MTTR) from 6 hours to 1.5 hours (75% reduction) and improved system reliability from 95% to 99.5% uptime through comprehensive observability and proactive monitoring.
I increased team sprint velocity by 35% and reduced sprint planning time by 50% through improved Agile practices and streamlined communication workflows.
I improved entity matching accuracy from 82% to 96% and reduced processing time by 65% through optimized probabilistic algorithms and distributed processing.
I reduced content delivery latency by 60% (from 800ms to 320ms) and decreased CDN costs by 40% through optimized caching strategies and edge computing.
I reduced overall AWS costs by 45% ($50K to $27.5K monthly) and improved budget forecast accuracy from 75% to 95% through comprehensive cost tagging and resource optimization.
Tech Stack: Custom CRM, AI-Powered Outreach, Network Intelligence, Dataset Enrichment, External Data Integration, Relationship Analysis, Opportunity Intelligence, Personalized Outreach, Machine Learning, Predictive Analytics, Data Enrichment, CRM Development, Computer Vision, Image Analysis, Document Processing, Graph Algorithms, Shortest Path, AWS Glue, Data Management, Data Lake, Data Pipeline, Data Modeling, AWS Lambda, AWS SQS, ETL, Looker, AWS Lambda, AWS SQS, AWS SNS, AWS DynamoDB, AWS Elasticsearch, Kibana, AWS S3, AWS Glue, PySpark, AWS Lambda, AWS Redshift, Business Intelligence, AWS Athena, VPC, AWS Cognito, AWS Lambda, Google Oauth, Audit Log, AWS AppSync, GraphQL, Node.js, JavaScript, React, TypeScript, Unit Tests, Functional Tests, Stress Tests, Regression Tests, CI/CD, TDD, Jira, AWS CloudWatch Logs, AWS CloudWatch Metrics, AWS CloudWatch Insights, AWS CloudWatch Alerts, AWS X-Ray, Agile, Scrum, Sprint Planning, Meetings Optimization, Issue Tracking, Confluence, Deterministic Matching, Probabilistic Matching, Distributed Lookup Table, AWS Glue Find Matches, Lookup Tables, AWS S3, AWS Cloud Front, AWS Lambda@Edge, AWS Tags, AWS Organizations
2019 - 2020 · Full-Stack Engineer · ConCntric
San Francisco, US
ConCntric provides pre-construction project portfolio management tools for the architecture, engineering, and construction industries.
I designed and deployed distributed data pipelines using Python and AWS Serverless architecture. I integrated observability, unit testing, CI/CD pipelines, and Slack alerts for end-to-end monitoring and traceability.
I implemented a Lambda-based recommendation engine with collaborative filtering and model evaluation via NRMSE and novelty metrics. I integrated Algolia for search indexing and relevance tuning.
I designed an end-to-end NLP system to extract structured data from semi-structured HTML using SpaCy, Keras, and regex parsing. I employed SpaCy, Keras, and AWS Comprehend to support data classification, entity recognition, and semantic search.
I built and deployed an interactive React marketplace frontend with Redux, Saga, and Stripe Connect. I enabled seamless payments, authentication, and real-time notifications via Firebase and AWS Amplify.
I boosted runtime efficiency by refactoring Python data pipelines with Cython acceleration and asynchronous programming patterns. I leveraged profiling tools and migrated to compiled modules to boost efficiency across pipelines.
I created automated QA pipelines with Cypress, GitHub Actions, and Slack alerts to ensure continuous delivery and rapid feedback loops. I implemented data quality acceptance checks to prevent drift and maintain ML model accuracy.
I operated as a "bridge" engineer, translating data science proofs-of-concept into production-ready microservices that the rest of the team could support.
I advocated for better observability across the stack, turning "it feels slow" complaints into measurable latency charts and targeted fixes.
I reduced pipeline execution time by 50% (from 4 hours to 2 hours) and achieved 99.9% reliability through serverless architecture and comprehensive monitoring.
I increased recommendation click-through rate by 42% and reduced search latency by 55% (from 220ms to 99ms) through optimized collaborative filtering algorithms and Algolia integration.
I improved data extraction accuracy from 72% to 91% and reduced processing time by 70% through optimized NLP pipelines and entity recognition models.
I increased transaction completion rate by 38% and reduced payment processing errors by 85% through optimized payment flows and real-time error handling.
I improved pipeline performance by 5x (from 2 hours to 24 minutes) and reduced memory usage by 40% through Cython optimization and asynchronous processing.
I increased test coverage from 55% to 90% and reduced production bugs by 75% through comprehensive automated testing and data quality checks.
Tech Stack: Python, sls, AWS Lambda, CloudWatch, AWS SQS, AWS SNS, AWS API Gateway, AWS SES, AWS Batch, Dashbord, Docker, AuroraDB, AWS RDS, AWS Cloud Front, Automated Tests, CI/CD, Slack API, Salesforce, Search Indexing, Content Ranking, Algolia, Collaborative Filtering, NumPy, Matplotlib, NRMSE, Entropy, Novelty, Diversity, Serendipity, Web Crawling, SpaCy, Keras, OpenCV, Airtable, NetworkX, nltk, JellyFish, Gensim, NER, Regular Expressions, AWS Comprehend, AWS Rekognition, Snowflake, Node.js, JavaScript, React, react-redux, react-saga, axios, AWS Amplify, StripeJS, Stripe Connect, Firebase Push Notifications, Firebase Authentication, CPython, C, C++, ctypes, Python.h, Cython, setup.py, cProfile, FFMPEG, asyncio, aiohttp, aiofiles, Cypress, Unit Tests, Integration Tests, Functional Tests
2016 - 2019 · Data Engineer · Ampush
San Francisco, US
Ampush delivers data-driven performance marketing and customer acquisition strategies for leading brands.
I engineered experimentation and user analytics backend in Flask with scalable AWS integration — enabled granular A/B testing and real-time metrics. I designed backend reporting APIs and implemented exception handling and i18n features across distributed services.
I collaborated with global engineering teams using Agile methods (Scrum, Kanban, Sprints). I participated in code reviews, pull requests, and documentation using Jira and Confluence.
I built scalable analytics backend using Flask APIs and AWS stack (Lambda, EC2, RDS), enabling real-time data access and reporting. I enabled secure and scalable data workflows.
I led transition from monolith to microservices using AWS ECS, SQS, and Docker. Focused on fault tolerance, eventual consistency, and clean architectural principles.
I architected hybrid storage systems with PostgreSQL, Cassandra, DynamoDB, and Elasticsearch for real-time querying and NoSQL/relational workloads. I used DBT for data transformations and NoSQL architecture.
I strengthened software quality with automated tests, CI pipelines, and fault-monitoring tools like Sentry and Splunk. I enhanced reliability across microservices.
I integrated multi-channel attribution APIs (Google Ads, Facebook, AppsFlyer) to unify performance tracking across ad platforms with Tableau dashboards. I collaborated with business stakeholders to optimize customer LTV, RPA, and CPA through analytics dashboards and ad performance APIs.
I built secure microservices payment infrastructure with Stripe and Shopify APIs, managing compliance, tokenization, and recurring billing. I managed subscriptions, refunds, compliance, and tokenized transactions securely.
I created automated QA pipelines with Cypress, GitHub Actions, and Slack alerts to ensure continuous delivery and rapid feedback loops. I ensured application stability post-deployment with CI workflows and monitoring.
I navigated significant time-zone differences (SF vs. remote teams) by adopting asynchronous communication flows (RFCs, documented handoffs) that kept velocity high.
I acted as the 'glue' between product requests and engineering reality, often negotiating scope down to MVP to meet marketing campaign deadlines.
I increased API throughput by 3x (from 1K to 3K requests/second) and reduced response latency by 45% (from 180ms to 99ms) through optimized Flask architecture and AWS integration.
I improved team productivity by 30% and reduced sprint planning overhead by 40% through optimized Agile workflows and cross-team collaboration.
I reduced infrastructure costs by 50% and improved system scalability to handle 10x traffic growth through optimized AWS architecture and auto-scaling strategies.
I reduced deployment time by 70% (from 2 hours to 36 minutes) and improved system reliability from 96% to 99.8% uptime through microservices architecture and fault-tolerant design.
I improved query performance by 4x (from 500ms to 125ms average) and reduced database costs by 35% through optimized hybrid storage architecture and data partitioning strategies.
I increased test coverage from 40% to 85% and reduced production incidents by 80% through comprehensive automated testing and proactive monitoring.
I improved customer LTV by 25% and reduced CPA by 30% through data-driven attribution modeling and real-time analytics dashboards.
I reduced payment processing failures by 90% and improved transaction security compliance to 100% through secure tokenization and comprehensive compliance checks.
I increased automated test coverage from 50% to 88% and reduced regression bugs by 82% through comprehensive CI/CD pipelines and automated testing.
Tech Stack: Python, Flask, REST API, Python-Flask-Restful, Flask-Restless, OpenPyXL, boto3, multi-threading, Python3 Eggs, Exception Handling, Error Codes, i18n & l18n, Sprints, Scrum, Kanban, Documentation, JIRA, Confluence, Pull Requests, Code Reviews, AWS EC2, AWS Elastic Beanstalk, AWS Route 53, AWS DynamoDB, AWS RDS, AWS S3, AWS Lambda, AWS SES, AWS SimpleDB, AWS ECS, AWS SQS, AWS SNS, Docker, HashCorp Consul, Eventual Consistency, Fault Tolerance, Idempotence Principle, Single Responsability Principle, Independence Principle, Apacha Cassandra, Elasticsearch, AWS DynamoDB, PostgreSQL, AWS RDS, DBT, NoSQL, Unit Tests, Integration Tests, Stress Tests, Longevity Tests, CircleCI, Rollbar, Sentry, Splunk, AWS CloudWatch Alerts, Fault Tolerance Analysis, SQL, Google Adwords API, Google Analytics API, Facebook Marketing API, Facebook Messenger API, AppsFlyer API, Outbrain API, Yahoo Gemini API, Tableau, Knowi, Mailchimp API, Spend, Impressions, Clicks, Conversion Rate, RPA, CPA, LTV, Retention, A/B Testing, Shopify API, ReCharge Payments API, Stripe API, Online Payments Processing, Credit Card Tokenization, Compliance, Charges Management, Subscription Management, Refund Policy, E2E, GitHub Actions, Slack Alerts, Feedback Loops, CD, Rollbar, Sentry, Splunk, AWS CloudWatch Alerts, Stability
2010 - 2016 · Certified IT Specialist · IBM
Buenos Aires, Argentina
IBM provides cloud computing, data analytics, and IT infrastructure services to clients worldwide.
I provided UNIX system administration for global banking clients, managing Red Hat Enterprise Linux 6, 7 & 8 (Red Hat), SuSE Linux Enterprise Server 11 (SuSE), IBM AIX 5.3 & 6.1 (AIX), and Oracle Solaris 10 (Solaris) systems with Oracle Virtual Box and KVM Virtualization (KVM). I automated tasks using Bash and KSH scripting.
I led successful data center migration for American Express. I handled incident, patch, and disaster recovery procedures using ITSM tools like Service Now and BMC Remedy and WebSphere Application Server (WAS). I provided English-language customer support for American Express customers.
I configured and managed core networking services (DNS, DHCP, LDAP, SSL). I diagnosed connectivity issues using netstat, traceroute, and nmap.
I provisioned and managed storage using Veritas Volume Manager (VxVM), Linux Volume Manager (LVM), LVM 2, AIX Volume Manager, EMC Storage Area Network (SAN), EMC Network Area Storage (NAS), and IBM Global Parallel File System (GPFS). I enabled high availability for banking workloads.
I developed and maintained server automation scripts using Python, Perl, and Shell scripting for infrastructure management. I created ETL jobs and automated deployment processes to streamline operations for enterprise banking clients.
I built internal LAMP web applications and tools using Java Spring Boot, PHP, and Django. I implemented modular components with design patterns, created responsive frontends with HTML, CSS, jQuery, and Bootstrap for enterprise dashboards.
I administered Oracle, DB2, MySQL, and MongoDB databases. I ensured high availability and consistent backups.
I managed observability for 1,000+ distributed nodes using custom metrics, Sentry, and CloudWatch — improved MTTR and system resilience. I improved service reliability and early issue detection.
I standardized operations across diverse legacy systems by documenting runbooks and scripts, reducing dependency on 'hero' engineers.
I trained junior admins to handle routine alerts and patches, freeing up senior staff for complex migrations.
I reduced manual system administration tasks by 60% and improved system uptime from 98% to 99.5% through automation scripts and proactive monitoring for 1,000+ distributed nodes.
I completed zero-downtime data center migration for 500+ servers and reduced incident resolution time by 50% (from 4 hours to 2 hours average) through streamlined ITSM processes.
I reduced network-related incidents by 70% and improved DNS resolution time by 40% through optimized network configuration and proactive monitoring.
I improved storage utilization from 65% to 85% and reduced storage-related downtime by 90% through optimized provisioning and high-availability configurations.
I reduced manual server management time by 75% and improved deployment consistency from 85% to 98% through comprehensive automation scripts.
I reduced application development time by 40% and improved code reusability by 60% through modular design patterns and component-based architecture.
I improved database performance by 35% and achieved 100% backup success rate with zero data loss through optimized database configurations and automated backup strategies.
I reduced mean time to resolution (MTTR) from 8 hours to 2 hours (75% reduction) and improved system reliability from 95% to 99.2% uptime through comprehensive observability and proactive monitoring for 1,000+ distributed nodes.
Tech Stack: Red Hat, AIX, SuSE, Solaris, systemd, File System Permissions, Bash, Korn Shell, Oracle Virtual Box, KVM, Troubleshooting, Change Management, Patch Automation, Service Now, Manage Now, BMC Remedy, ITSM, Backup, Restore, Disaster Recovery, WAS, DHCP Server, DNS Server, SSO Server, LDAP Server, FTP, SSL Certificates, nmap, ssh, Networking, VxVM, LVM, LVM2, SAN, NAS, GPFS, Python, Perl, Shell Scripting, ETL, CICD, Java, Spring Boot, PHP, Django, HTML, CSS, jQuery, Bootstrap, Web Scraping, Connection Pool, Apache HTTP Server (IHS), Oracle, IBM DB2, MySQL, MongoDB, QA, Monitoring, Alerts
Experience

AI Tech Lead @ Laminr
San Francisco, US
2024 - Today
Laminr is an innovative AI company specializing in developing advanced agent-based solutions to automate complex business processes and workflows.
I established a comprehensive mentorship program focused on knowledge transfer to engineering team members, translating complex business requirements into executable technical tasks. I conducted regular educational meetings, live-coding sessions, pair-programming workshops, and coding bootcamps to foster team collaboration and accelerate skill development across the organization.
Product RequirementsTechnical LeadershipMentorshipArchitecture DesignI architected and shipped a production fleet of autonomous AI agents (agentic AI) for financial services, built on the Google Agent Development Kit (ADK) and Vertex AI. I designed and delivered a multi-agent system of named, Slack-resident teammates — a project manager (Scotty), a customer-support agent (Uhura), a release engineer (James), a DevOps / technical-support agent (Geordi), a QA / testing agent (Tuvok), and a software-engineering agent (Wesley) — each a standalone FastAPI service deployed independently on Cloud Run so a bug in one can never take the others down. Every agent shares the same architecture: an ADK root agent composed from a Role + Soul prompt pair, specialized sub-agents (planner, messenger, manager, documenter, validator) for orchestration, and tool calling / function calling over the Model Context Protocol (MCP) against Slack, Shortcut, Outline, GitHub, Sentry, Cloud Run, Datadog, and the Laminr tenant API.
Agentic AIAI AgentsMulti-Agent SystemsLLM AgentsGoogle ADKVertex AIMCPAgent OrchestrationFastAPICloud RunI designed the fleet's shared "teammate" behaviors so the agents operate as a team rather than as isolated bots. I built a markdown-based agent skills system (one skill per file, loaded at build time into the root instruction) covering attention, prioritization, estimation, and role-specific playbooks; a hub-and-spoke escalation model where every spoke knows only that Scotty is its PM and Scotty alone holds the roster; a daily collaborative standup and a #deepmind collaboration channel where agents recruit each other for help; and cron-fired scheduled activities (Cloud Scheduler → /internal/ask with stable per-activity session ids) for standups, pre-release summaries, production monitoring, and twice-daily ops sweeps. I drove the architectural decision to migrate "classify-and-decide" sub-agents into skills to cut an LLM hop, token cost, and a failure surface per turn.
Agent SkillsMulti-Agent CollaborationHub-and-SpokeEscalation RoutingScheduled AgentsCloud SchedulerSub-Agent DesignPrompt EngineeringI engineered the agent memory management architecture: a two-tier design with per-conversation session memory and a shared, organization-wide long-term memory backed by Vertex AI Memory Bank, so every agent accumulates company knowledge across all conversations. I implemented semantic memory recall with Retrieval-Augmented Generation (RAG), embeddings, and vector search, plus context engineering (session-key design, full-thread context loading) that eliminated lost-context failures across Slack DMs, threads, and channels.
LLM MemoryLong-Term MemoryRAGEmbeddingsVector SearchContext EngineeringVertex AI Memory BankSemantic SearchI designed the agent authorization and safety layer with human-in-the-loop (HITL) controls: AI agents drive high-stakes workflows (production deploys, release PRs) to a merge-ready state while final approval stays human-gated behind explicit feature flags and approval gates. I enforced least-privilege tool surfaces per agent, user allowlists evaluated before any LLM call, idempotent send-path deduplication, and prompt-plus-code defense-in-depth response policies — AI guardrails enforced by the tooling layer, not the model.
Human-in-the-Loop (HITL)AI GuardrailsAI SafetyResponsible AIAI GovernanceAccess ControlLeast PrivilegeI built hallucination protection into every agent: a read-only validator sub-agent acts as an anti-hallucination gate, verifying that every entity named in a draft reply (tickets, documents, services, releases, packages) actually exists against this turn's tool-call journal and live APIs before the reply is sent. I combined this grounding layer with LLM evaluation pipelines, prompt engineering standards, and LLMOps practices for tracing, regression-testing, and monitoring agent behavior in production.
Hallucination DetectionAI GroundingLLM EvaluationPrompt EngineeringLLMOpsAI ReliabilityTrustworthy AII engineered the agents' memory and context layer on Vertex AI Memory Bank: a two-tier design with per-conversation session memory and a shared, organization-wide long-term bucket, plus per-member long-term buckets so each agent adapts its behaviour to whoever it is talking to. I implemented semantic recall with Retrieval-Augmented Generation (RAG), embeddings, and vector search, and solved two production-grade context bugs — binding per-turn Slack origin in a session-id-keyed store (ContextVar values do not survive ADK's task/thread boundary) and treating the GCS session pointer as a recoverable cache by stamping the Slack surface key into Vertex session state and healing the pointer on a lookup miss.
Vertex AI Memory BankLong-Term MemoryPer-Member MemoryRAGEmbeddingsVector SearchContext EngineeringSession ManagementI built the agents' authorization, ingress, and reliability layer that lets the fleet talk to each other but to nothing else. I implemented a layered Slack ingress gate (self-drop, sibling-bot allowlist, channel allowlist, and an @laminr.ai DM email-domain gate) that runs before the LLM is ever loaded, a narrow response policy so the bots never barge into deploy threads or side conversations, and send-path deduplication (SHA-256 fingerprint over channel/thread/text, backed by GCS, fail-open) so an LLM retry or redelivered Slack event can never post the same message twice. I added a code-side single-fire guard that caches a gate sub-agent's verdict and short-circuits repeat invocations to stop runaway LLM loops.
Access ControlAllowlistsIdempotencyDeduplicationAI GuardrailsDefense in DepthSlack APIRate LimitingI developed Computer Vision and document AI capabilities for automated financial document processing, with end-to-end pipelines for image-to-text data extraction (OCR) using state-of-the-art models, and integrated multi-modal AI systems with business workflows for seamless automation.
Computer VisionOCRDocument AILangChainPyTorchTensorFlowI led the design and deployment of the platform's Python backend on Django 5: I built REST APIs with Django REST Framework (DRF) and JWT authentication, asynchronous background processing with Celery workers and scheduled tasks over Redis, and a PostgreSQL data layer with Pydantic-validated domain models. I extended the Django Admin for internal operations and connected business intelligence dashboards (Metabase) directly to the Django data model to drive operational insights.
PythonDjangoDjango REST FrameworkCeleryPostgreSQLRedisPydanticMetabaseI architected and implemented modern, responsive web applications using React Workspaces with PNPM monorepo setup, Zustand for state management, and React Query for efficient data fetching. I leveraged TypeScript for type safety and Tailwind CSS for rapid UI development, ensuring maintainable and scalable frontend architecture across multiple packages.
ReactPNPMMonorepoZustandReact QueryAxiosTypeScriptTailwindI architected and implemented cloud-native infrastructure using Pulumi for IaC, deploying services on GCP (Cloud Run, GKE, Cloud SQL, Memorystore Redis) with zero-downtime deployments. I orchestrated containerized applications on Google Kubernetes Engine (GKE) — Google Cloud's managed Kubernetes service that automates cluster provisioning, autoscaling, upgrades, and security patching — using it to run scalable microservices with horizontal pod autoscaling, node auto-provisioning, workload identity for secure GCP access, and rolling deployments across multi-zone clusters. I established CI/CD pipelines and infrastructure automation for seamless deployments and scaling.
PulumiCloud RunGKEKubernetesCloud SQLRedisGoogle Cloud MonitoringCI/CDInfrastructure as Code (IaC)Google Cloud Platform (GCP)I built a comprehensive QA framework with Playwright for E2E testing and integrated monitoring solutions (Datadog, Sentry) for real-time observability and incident response. I implemented automated testing pipelines and established monitoring best practices for production systems.
PlaywrightSentryDatadogE2ECloud MonitoringAutomated TestsI turned ‘what could go wrong’ concerns into concrete mitigations (tests, monitoring, rollout plans), reducing incidents while maintaining shipping cadence.
Risk MitigationRollout PlansIncident PreventionI shipped a six-agent production fleet of autonomous Slack teammates — a project manager (Scotty), a customer-support agent (Uhura), a release engineer (James), a DevOps / technical-support agent (Geordi), a QA / testing agent (Tuvok), and a software-engineering agent (Wesley) — each deployed as an independent Cloud Run service on Google ADK and Vertex AI.
Multi-Agent FleetGoogle ADKCloud RunI built the customer-support agent (Uhura) on the Laminr tenant API, fielding loan-package, eligibility, conformance, and income questions in Slack and human-gating high-stakes reprocessing behind cryptographic Approve/Dismiss authorization.
Customer Support AgentHuman-in-the-LoopTenant APII built the release-manager agent (James) that drives the main → prod deploy end-to-end — gate checks, release-PR open/review, GitHub Actions monitoring, and real-time #prod-deploy updates — leaving only the human-authorized merge click behind an Approve/Dismiss gate.
Release ManagerRelease EngineeringCI/CDI built the project-manager agent (Scotty) as the fleet's hub: planning and scoping, team coordination, the daily collaborative standup, capability-gap tracking, and Shortcut / Outline documentation hand-offs, holding the only roster the other agents escalate to.
Project Manager AgentOrchestrationHub-and-SpokeI built the DevOps / technical-support agent (Geordi) over Sentry, Cloud Run / Cloud Logging, Cloud Run Jobs, and Datadog, triaging production-error and monitor alerts in-thread and running twice-daily silent-by-default ops sweeps that page humans only when production is bleeding.
Technical Support AgentDevOpsIncident TriageI achieved a 40% reduction in onboarding time for new engineers and increased team velocity by 25% within 6 months through structured knowledge transfer.
Ramp-up TimeTeam VelocityStructured LearningI reduced document processing time by 80% (from 5 minutes to 1 minute per document) and increased automation coverage from 30% to 85% of business workflows within 4 months.
Processing SpeedAutomationWorkflowsI increased API response time by 60% (from 500ms to 200ms average) and reduced infrastructure costs by 35% through optimized database queries and caching strategies.
API PerformanceCachingCost OptimizationI reduced bundle size by 45% and improved page load time by 50% (from 3.2s to 1.6s) through code splitting and lazy loading optimizations.
Frontend PerformanceCode SplittingLazy LoadingI achieved 99.9% uptime and reduced deployment time from 45 minutes to 8 minutes (82% reduction) through automated CI/CD pipelines and infrastructure as code.
UptimeDeployment PipelinesIaCI reduced production incidents by 70% and decreased mean time to resolution (MTTR) from 4 hours to 45 minutes through comprehensive test coverage and proactive monitoring.
MTTRTest CoverageIncident Response
Blockchain Engineer @ Makersplace
San Francisco, US
2022 - 2024
MakersPlace is a digital creation platform powered by blockchain, enabling creators to sell unique digital artwork.
I built end-to-end digital asset infrastructure integrating Django backends with Solidity smart contracts and Rust-based logic for Web3 protocols. I led NFT and phygital asset deployments using web3.js, Alchemy, and IPFS, integrating smart contracts with full-stack applications. I partnered with cross-functional teams (marketing, sales) to launch blockchain-based digital campaigns that increased user engagement and retention.
web3.jsethers.jsAlchemyMoralisEthereumEtherscanIPFSSolidityRustMetaMaskCoinbaseWallet ConnectSolscanRoyalty RegistryI diagnosed and resolved critical failures in blockchain workflows, including transaction validation, IPFS metadata syncing, and dynamic gas optimization. I designed fault-tolerant microservices for real-time blockchain transaction monitoring and distributed data pipelines.
PythonDjangoCeleryUnit TestsAirflowI developed production-grade MLOps pipeline on AWS for scalable model lifecycle management, leveraging Docker, Kubernetes, and SageMaker. I enabled model versioning and continuous monitoring for production ML workflows, ensuring data drift detection and model rollback.
AWS SageMakerTensorFlowMLOpsgRPCDockerKubernetesI automated deployment infrastructure using AWS CDK and CI/CD pipelines (GitHub Actions, Elastic Beanstalk, ECR), achieving zero-downtime rollouts. I dockerized applications and managed deployment environments using Elastic Beanstalk, ECR, RDS, and Opensearch.
AWS CDKAWS Elastic BeanstalkAWS ECRAWS RDSAWS OpensearchAWS ElasticacheAWS S3AWS CloudfrontAWS DMSI directed enterprise-scale data migration to GCP BigQuery, optimizing ETL pipelines with Data Fusion for low-latency analytics. I enabled real-time data access for business intelligence.
BigQueryData FusionData StreamsI built full-spectrum test automation suite with Cypress, PyTest, and integration testing frameworks — enforced zero-regression policies pre-launch. I validated digital drops and NFT-related product features to ensure high quality and zero regression.
CypressUnit TestsIntegration TestsFunctional TestsI delivered under aggressive launch timelines by making explicit tradeoffs (guardrails, rollback plans, monitoring) that protected reliability while meeting drop deadlines.
Release ManagementRollbackReliabilityI partnered cross-functionally (marketing/sales + engineering) to ship blockchain features fast, while keeping transaction integrity high through automation and fault-tolerant services.
Cross-functionalTransaction IntegrityShip FastI increased transaction success rate from 85% to 98% and reduced gas costs by 40% through optimized smart contract design and dynamic gas pricing strategies.
Smart ContractsGas OptimizationI reduced system downtime by 90% (from 2% to 0.2% monthly) and improved transaction processing throughput by 3x through fault-tolerant architecture and optimized data pipelines.
ResilienceData PipelinesI reduced model deployment time from 2 weeks to 2 days (90% reduction) and improved model accuracy monitoring coverage from 40% to 95% through automated MLOps pipelines.
Model LifecycleModel DeploymentI achieved 100% zero-downtime deployments and reduced infrastructure provisioning time from 4 hours to 15 minutes (94% reduction) through infrastructure as code and automated CI/CD.
High AvailabilityIaCCICDI reduced data processing latency by 75% (from 4 hours to 1 hour) and decreased data warehouse costs by 50% through optimized ETL pipelines and query optimization.
ETLQuery OptimizationI increased test coverage from 45% to 92% and reduced regression bugs in production by 85% through comprehensive automated testing.
Test CoverageRegression
Data Engineer @ Rings AI
San Francisco, US
2020 - 2022
An AI-powered platform for opportunity intelligence through relationship data.
I architected and developed a custom CRM platform designed to improve outreach effectiveness using AI-driven insights from network relationship data. I implemented intelligent dataset enrichment by integrating multiple external data sources, enabling personalized outreach strategies and opportunity intelligence. I built machine learning models to analyze relationship patterns and predict optimal engagement approaches. I integrated computer vision capabilities for automated profile image analysis and document processing to enhance contact data quality.
Custom CRMAI-Powered OutreachNetwork IntelligenceDataset EnrichmentExternal Data IntegrationRelationship AnalysisOpportunity IntelligencePersonalized OutreachMachine LearningPredictive AnalyticsData EnrichmentCRM DevelopmentComputer VisionImage AnalysisDocument ProcessingI built real-time distributed graph algorithm in Spark for relationship path analysis. I streamlined data materialization using AWS Glue, SQS, and ETL processes.
Graph AlgorithmsShortest PathAWS GlueData ManagementData LakeData PipelineData ModelingAWS LambdaAWS SQSETLLookerI designed high-throughput serverless backend using AWS Lambda, event-driven SQS/SNS queues, and Elasticsearch for log indexing and traceability. I ensured high availability and scalability across the architecture.
AWS LambdaAWS SQSAWS SNSAWS DynamoDBAWS ElasticsearchKibanaI constructed scalable ETL pipelines using AWS Glue and Athena to support Redshift-based data warehousing and interactive querying. I improved data warehouse performance and reporting efficiency.
AWS S3AWS GluePySparkAWS LambdaAWS RedshiftBusiness IntelligenceAWS AthenaI optimized cloud network infrastructure with custom VPC architectures, reducing inter-zone data transfer costs by 30% via NAT gateway tuning. I reduced data transfer costs while ensuring security.
VPCI integrated secure authentication and audit logging using AWS Cognito, Google OAuth 2.0, and serverless event-driven Lambda functions. I ensured compliance and traceability.
AWS CognitoAWS LambdaGoogle OauthAudit LogI implemented micro-frontends in React with GraphQL over AWS AppSync to support real-time UI rendering and scalable user data interactions. I integrated robust data flows using Node and TypeScript.
AWS AppSyncGraphQLNode.jsJavaScriptReactTypeScriptI created automated QA pipelines with Cypress, GitHub Actions, and Slack alerts to ensure continuous delivery and rapid feedback loops. I managed CI/CD workflows to maintain code quality.
Unit TestsFunctional TestsStress TestsRegression TestsCI/CDTDDI performed production diagnostics using AWS observability stack (CloudWatch, X-Ray, custom metrics), producing detailed RCA reports. I delivered actionable RCA reports and fixes.
JiraAWS CloudWatch LogsAWS CloudWatch MetricsAWS CloudWatch InsightsAWS CloudWatch AlertsAWS X-RayI worked in Agile teams using Scrum, Jira, and Confluence. I optimized sprint velocity and stakeholder communication.
AgileScrumSprint PlanningMeetings OptimizationIssue TrackingConfluenceI built probabilistic matching algorithms using AWS Glue and distributed lookups. I enhanced data integration across sources.
Deterministic MatchingProbabilistic MatchingDistributed Lookup TableAWS Glue Find MatchesLookup TablesI deployed secure CDN with Lambda@Edge and CloudFront. I reduced latency and improved user content delivery.
AWS S3AWS Cloud FrontAWS Lambda@EdgeI applied cost tags and managed resources with AWS Organizations. I enhanced budget accountability and forecast accuracy.
AWS TagsAWS OrganizationsI collaborated effectively with very direct, high-bar engineers by focusing on evidence: benchmarks, RFCs, and reproducible experiments—turning sharp debate into better architecture.
RFCsEvidence-basedArchitectureI navigated high-stakes stakeholder pressure by documenting tradeoffs, defining objective success metrics, and protecting delivery from last-minute churn.
Stakeholder ManagementTradeoffsMetricsI increased outreach conversion rates by 65% and reduced data enrichment time from 2 hours to 15 minutes per contact through AI-powered automation.
ConversionEnrichment ThroughputAutomationI reduced graph computation time by 70% (from 30 minutes to 9 minutes) and improved data accuracy from 78% to 95% through optimized graph algorithms and real-time processing.
Graph PerformanceReal-timeI achieved 99.95% uptime and reduced infrastructure costs by 60% compared to traditional EC2-based architecture while handling 10x traffic spikes.
UptimeCost OptimizationI reduced ETL processing time by 55% (from 6 hours to 2.7 hours) and decreased query latency by 40% through optimized data partitioning and columnar storage strategies.
Pipeline PerformanceQuery LatencyI achieved 30% cost reduction in data transfer costs ($15K to $10.5K monthly) and improved network latency by 25% through optimized VPC architecture and NAT gateway configuration.
VPCCost ReductionI reduced authentication failures by 80% and achieved 100% audit trail coverage for all user actions, ensuring full compliance with security requirements.
AuthComplianceI reduced API response time by 50% (from 400ms to 200ms) and decreased frontend bundle size by 35% through GraphQL query optimization and code splitting.
GraphQLCode SplittingI increased test automation coverage from 30% to 88% and reduced time-to-feedback from 2 days to 2 hours through automated CI/CD pipelines.
Test AutomationFeedback LoopsI reduced mean time to resolution (MTTR) from 6 hours to 1.5 hours (75% reduction) and improved system reliability from 95% to 99.5% uptime through comprehensive observability and proactive monitoring.
MTTRObservabilityI increased team sprint velocity by 35% and reduced sprint planning time by 50% through improved Agile practices and streamlined communication workflows.
Sprint VelocityCommunicationI improved entity matching accuracy from 82% to 96% and reduced processing time by 65% through optimized probabilistic algorithms and distributed processing.
Entity MatchingDistributed ProcessingI reduced content delivery latency by 60% (from 800ms to 320ms) and decreased CDN costs by 40% through optimized caching strategies and edge computing.
CDNCachingI reduced overall AWS costs by 45% ($50K to $27.5K monthly) and improved budget forecast accuracy from 75% to 95% through comprehensive cost tagging and resource optimization.
Budget AccuracyResource Optimization
Full-Stack Engineer @ ConCntric
San Francisco, US
2019 - 2020
ConCntric provides pre-construction project portfolio management tools for the architecture, engineering, and construction industries.
I designed and deployed distributed data pipelines using Python and AWS Serverless architecture. I integrated observability, unit testing, CI/CD pipelines, and Slack alerts for end-to-end monitoring and traceability.
PythonslsAWS LambdaCloudWatchAWS SQSAWS SNSAWS API GatewayAWS SESAWS BatchDashbordDockerAuroraDBAWS RDSAWS Cloud FrontAutomated TestsCI/CDSlack APISalesforceI implemented a Lambda-based recommendation engine with collaborative filtering and model evaluation via NRMSE and novelty metrics. I integrated Algolia for search indexing and relevance tuning.
Search IndexingContent RankingAlgoliaCollaborative FilteringNumPyMatplotlibNRMSEEntropyNoveltyDiversitySerendipityI designed an end-to-end NLP system to extract structured data from semi-structured HTML using SpaCy, Keras, and regex parsing. I employed SpaCy, Keras, and AWS Comprehend to support data classification, entity recognition, and semantic search.
Web CrawlingSpaCyKerasOpenCVAirtableNetworkXnltkJellyFishGensimNERRegular ExpressionsAWS ComprehendAWS RekognitionSnowflakeI built and deployed an interactive React marketplace frontend with Redux, Saga, and Stripe Connect. I enabled seamless payments, authentication, and real-time notifications via Firebase and AWS Amplify.
Node.jsJavaScriptReactreact-reduxreact-sagaaxiosAWS AmplifyStripeJSStripe ConnectFirebase Push NotificationsFirebase AuthenticationI boosted runtime efficiency by refactoring Python data pipelines with Cython acceleration and asynchronous programming patterns. I leveraged profiling tools and migrated to compiled modules to boost efficiency across pipelines.
CPythonCC++ctypesPython.hCythonsetup.pycProfileFFMPEGasyncioaiohttpaiofilesI created automated QA pipelines with Cypress, GitHub Actions, and Slack alerts to ensure continuous delivery and rapid feedback loops. I implemented data quality acceptance checks to prevent drift and maintain ML model accuracy.
CypressUnit TestsIntegration TestsFunctional TestsI operated as a "bridge" engineer, translating data science proofs-of-concept into production-ready microservices that the rest of the team could support.
Bridge EngineerMicroservicesProductionI advocated for better observability across the stack, turning "it feels slow" complaints into measurable latency charts and targeted fixes.
ObservabilityLatencyMetricsI reduced pipeline execution time by 50% (from 4 hours to 2 hours) and achieved 99.9% reliability through serverless architecture and comprehensive monitoring.
ServerlessReliabilityI increased recommendation click-through rate by 42% and reduced search latency by 55% (from 220ms to 99ms) through optimized collaborative filtering algorithms and Algolia integration.
RecommendationsCTRI improved data extraction accuracy from 72% to 91% and reduced processing time by 70% through optimized NLP pipelines and entity recognition models.
NLPEntity RecognitionI increased transaction completion rate by 38% and reduced payment processing errors by 85% through optimized payment flows and real-time error handling.
PaymentsError HandlingI improved pipeline performance by 5x (from 2 hours to 24 minutes) and reduced memory usage by 40% through Cython optimization and asynchronous processing.
PerformanceCythonI increased test coverage from 55% to 90% and reduced production bugs by 75% through comprehensive automated testing and data quality checks.
Test CoverageQuality
Data Engineer @ Ampush
San Francisco, US
2016 - 2019
Ampush delivers data-driven performance marketing and customer acquisition strategies for leading brands.
I engineered experimentation and user analytics backend in Flask with scalable AWS integration — enabled granular A/B testing and real-time metrics. I designed backend reporting APIs and implemented exception handling and i18n features across distributed services.
PythonFlaskREST APIPython-Flask-RestfulFlask-RestlessOpenPyXLboto3multi-threadingPython3 EggsException HandlingError Codesi18n & l18nI collaborated with global engineering teams using Agile methods (Scrum, Kanban, Sprints). I participated in code reviews, pull requests, and documentation using Jira and Confluence.
SprintsScrumKanbanDocumentationJIRAConfluencePull RequestsCode ReviewsI built scalable analytics backend using Flask APIs and AWS stack (Lambda, EC2, RDS), enabling real-time data access and reporting. I enabled secure and scalable data workflows.
AWS EC2AWS Elastic BeanstalkAWS Route 53AWS DynamoDBAWS RDSAWS S3AWS LambdaAWS SESAWS SimpleDBI led transition from monolith to microservices using AWS ECS, SQS, and Docker. Focused on fault tolerance, eventual consistency, and clean architectural principles.
AWS ECSAWS SQSAWS SNSDockerHashCorp ConsulEventual ConsistencyFault ToleranceIdempotence PrincipleSingle Responsability PrincipleIndependence PrincipleI architected hybrid storage systems with PostgreSQL, Cassandra, DynamoDB, and Elasticsearch for real-time querying and NoSQL/relational workloads. I used DBT for data transformations and NoSQL architecture.
Apacha CassandraElasticsearchAWS DynamoDBPostgreSQLAWS RDSDBTNoSQLI strengthened software quality with automated tests, CI pipelines, and fault-monitoring tools like Sentry and Splunk. I enhanced reliability across microservices.
Unit TestsIntegration TestsStress TestsLongevity TestsCircleCIRollbarSentrySplunkAWS CloudWatch AlertsFault Tolerance AnalysisI integrated multi-channel attribution APIs (Google Ads, Facebook, AppsFlyer) to unify performance tracking across ad platforms with Tableau dashboards. I collaborated with business stakeholders to optimize customer LTV, RPA, and CPA through analytics dashboards and ad performance APIs.
SQLGoogle Adwords APIGoogle Analytics APIFacebook Marketing APIFacebook Messenger APIAppsFlyer APIOutbrain APIYahoo Gemini APITableauKnowiMailchimp APISpendImpressionsClicksConversion RateRPACPALTVRetentionA/B TestingI built secure microservices payment infrastructure with Stripe and Shopify APIs, managing compliance, tokenization, and recurring billing. I managed subscriptions, refunds, compliance, and tokenized transactions securely.
Shopify APIReCharge Payments APIStripe APIOnline Payments ProcessingCredit Card TokenizationComplianceCharges ManagementSubscription ManagementRefund PolicyI created automated QA pipelines with Cypress, GitHub Actions, and Slack alerts to ensure continuous delivery and rapid feedback loops. I ensured application stability post-deployment with CI workflows and monitoring.
E2EGitHub ActionsSlack AlertsFeedback LoopsCDRollbarSentrySplunkAWS CloudWatch AlertsStabilityI navigated significant time-zone differences (SF vs. remote teams) by adopting asynchronous communication flows (RFCs, documented handoffs) that kept velocity high.
RemoteRFCsAsyncI acted as the 'glue' between product requests and engineering reality, often negotiating scope down to MVP to meet marketing campaign deadlines.
StakeholderMVPScopeI increased API throughput by 3x (from 1K to 3K requests/second) and reduced response latency by 45% (from 180ms to 99ms) through optimized Flask architecture and AWS integration.
ThroughputBackendLatencyI improved team productivity by 30% and reduced sprint planning overhead by 40% through optimized Agile workflows and cross-team collaboration.
AgileProductivityCollaborationI reduced infrastructure costs by 50% and improved system scalability to handle 10x traffic growth through optimized AWS architecture and auto-scaling strategies.
Cost OptimizationAuto-scalingScalabilityI reduced deployment time by 70% (from 2 hours to 36 minutes) and improved system reliability from 96% to 99.8% uptime through microservices architecture and fault-tolerant design.
DeploymentResilienceUptimeI improved query performance by 4x (from 500ms to 125ms average) and reduced database costs by 35% through optimized hybrid storage architecture and data partitioning strategies.
Query PerformanceData PartitioningHybrid StorageI increased test coverage from 40% to 85% and reduced production incidents by 80% through comprehensive automated testing and proactive monitoring.
Test CoverageMonitoringI improved customer LTV by 25% and reduced CPA by 30% through data-driven attribution modeling and real-time analytics dashboards.
AttributionAnalyticsCustomer MetricsI reduced payment processing failures by 90% and improved transaction security compliance to 100% through secure tokenization and comprehensive compliance checks.
PaymentsSecurityTransaction IntegrityI increased automated test coverage from 50% to 88% and reduced regression bugs by 82% through comprehensive CI/CD pipelines and automated testing.
CI/CDRegression PreventionQA Pipelines
Certified IT Specialist @ IBM
Buenos Aires, Argentina
2010 - 2016
IBM provides cloud computing, data analytics, and IT infrastructure services to clients worldwide.
I provided UNIX system administration for global banking clients, managing Red Hat Enterprise Linux 6, 7 & 8 (Red Hat), SuSE Linux Enterprise Server 11 (SuSE), IBM AIX 5.3 & 6.1 (AIX), and Oracle Solaris 10 (Solaris) systems with Oracle Virtual Box and KVM Virtualization (KVM). I automated tasks using Bash and KSH scripting.
Red HatAIXSuSESolarissystemdFile System PermissionsBashKorn ShellOracle Virtual BoxKVMI led successful data center migration for American Express. I handled incident, patch, and disaster recovery procedures using ITSM tools like Service Now and BMC Remedy and WebSphere Application Server (WAS). I provided English-language customer support for American Express customers.
TroubleshootingChange ManagementPatch AutomationService NowManage NowBMC RemedyITSMBackupRestoreDisaster RecoveryWASI configured and managed core networking services (DNS, DHCP, LDAP, SSL). I diagnosed connectivity issues using netstat, traceroute, and nmap.
DHCP ServerDNS ServerSSO ServerLDAP ServerFTPSSL CertificatesnmapsshNetworkingI provisioned and managed storage using Veritas Volume Manager (VxVM), Linux Volume Manager (LVM), LVM 2, AIX Volume Manager, EMC Storage Area Network (SAN), EMC Network Area Storage (NAS), and IBM Global Parallel File System (GPFS). I enabled high availability for banking workloads.
VxVMLVMLVM2SANNASGPFSI developed and maintained server automation scripts using Python, Perl, and Shell scripting for infrastructure management. I created ETL jobs and automated deployment processes to streamline operations for enterprise banking clients.
PythonPerlShell ScriptingETLCICDI built internal LAMP web applications and tools using Java Spring Boot, PHP, and Django. I implemented modular components with design patterns, created responsive frontends with HTML, CSS, jQuery, and Bootstrap for enterprise dashboards.
JavaSpring BootPHPDjangoHTMLCSSjQueryBootstrapWeb ScrapingConnection PoolApache HTTP Server (IHS)I administered Oracle, DB2, MySQL, and MongoDB databases. I ensured high availability and consistent backups.
OracleIBM DB2MySQLMongoDBI managed observability for 1,000+ distributed nodes using custom metrics, Sentry, and CloudWatch — improved MTTR and system resilience. I improved service reliability and early issue detection.
QAMonitoringAlertsI standardized operations across diverse legacy systems by documenting runbooks and scripts, reducing dependency on 'hero' engineers.
RunbooksDocumentationI trained junior admins to handle routine alerts and patches, freeing up senior staff for complex migrations.
MentorshipKnowledge TransferOperationsI reduced manual system administration tasks by 60% and improved system uptime from 98% to 99.5% through automation scripts and proactive monitoring for 1,000+ distributed nodes.
AutomationUptimeAlertsI completed zero-downtime data center migration for 500+ servers and reduced incident resolution time by 50% (from 4 hours to 2 hours average) through streamlined ITSM processes.
MigrationHigh AvailabilityITSMI reduced network-related incidents by 70% and improved DNS resolution time by 40% through optimized network configuration and proactive monitoring.
NetworkingDNSIncident ManagementI improved storage utilization from 65% to 85% and reduced storage-related downtime by 90% through optimized provisioning and high-availability configurations.
StorageHigh AvailabilityProvisioningI reduced manual server management time by 75% and improved deployment consistency from 85% to 98% through comprehensive automation scripts.
Shell ScriptingDeploymentI reduced application development time by 40% and improved code reusability by 60% through modular design patterns and component-based architecture.
Design PatternsReusabilityModularityI improved database performance by 35% and achieved 100% backup success rate with zero data loss through optimized database configurations and automated backup strategies.
DatabaseBackupPerformanceI reduced mean time to resolution (MTTR) from 8 hours to 2 hours (75% reduction) and improved system reliability from 95% to 99.2% uptime through comprehensive observability and proactive monitoring for 1,000+ distributed nodes.
MTTRObservabilityReliability2024 · Computer Engineering
Valencia International University
I completed a final project focused on computational geometry, algorithmic analysis, and optimization algorithms in combinatorial space.
I can design and implement scalable software systems using formal methods, complexity analysis, and architecture patterns.
I can develop and operate distributed systems with concurrency, parallelism, and database and networking fundamentals.
I can manage the full software lifecycle and deliver projects aligned with business and technical requirements.
I can apply systems programming (C, Java, Python, Rust), operating systems, and computer architecture to production systems.
I can work across the stack from low-level systems to high-level applications using architecture, operating systems, and multiple languages.
I can reason about algorithmic complexity and choose appropriate data structures and algorithms for performance and maintainability.
I can write and review technical specifications and documentation grounded in formal methods and engineering practice.
I can use testing, refactoring, and design principles to identify and reduce technical debt and improve quality.
I can apply mathematical and statistical foundations (calculus, algebra, discrete math) to modeling and problem-solving in software systems.
I can design and train deep learning models using frameworks such as Keras, TensorFlow, and PyTorch for computer vision, NLP, and sequence modeling.
I can build agentic AI systems and custom agents (e.g. with LangChain) for code assistance, tool use, and autonomous workflows, similar to Cursor-style behavior.
2019 · Business Administration
UNLaM
I built a fintech company from scratch as my final project: business plan, financial projections, regulatory considerations, and go-to-market strategy.
I can manage people and teams: hiring, performance, and coordination aligned with organizational goals.
I can lead financial administration: budgeting, forecasting, cost allocation, and economic and financial modeling for planning and reporting.
I can align technical roadmaps with business goals using project and capital administration from the degree.
I can analyze financial statements, manage risk, and support decision-making with quantitative and process-optimization tools.
I can apply marketing strategies, market research, and positioning to support product and growth decisions in tech and startups.
I can interpret contracts, compliance requirements, and regulatory constraints in business and product contexts.
I can use applied statistics and quantitative methods for forecasting, reporting, and data-driven decisions.
I can optimize processes and allocate resources across teams or projects using cost and operations management.
I can contribute to audit, internal controls, and financial reporting in tech and startup environments.
2012 · Certificate in Advanced English
Cambridge University
I can communicate fluently with US-based teams and stakeholders in meetings, async channels, and written documentation.
I can lead or contribute to technical discussions, code reviews, sprint ceremonies, and RFCs in English with clarity and precision.
I can write clear technical documentation, incident reports, and proposals for distributed and cross-functional audiences.
I can collaborate effectively with Product, Design, and non-engineering partners in English without language barriers.
I can present to customers or partners and handle customer-facing communication when required by the role.
2008 · First Certificate in English
Cambridge University
I can follow technical discussions, stakeholder meetings, and standups in English and contribute to day-to-day collaboration.
I can participate in daily standups, retros, and cross-team conversations in English with confidence at B2 level.
I can write professional emails, tickets, and short documentation in English for remote and distributed teams.
I can engage with English-speaking clients or support when needed and understand requirements and feedback.
I can provide a strong, permanent foundation for further advancement to C1 (CAE) for more complex professional communication.
Education

2024
Computer Engineering
Valencia International UniversityI completed a final project focused on computational geometry, algorithmic analysis, and optimization algorithms in combinatorial space.
PythonAlgorithmsComputational GeometryOptimizationI can design and implement scalable software systems using formal methods, complexity analysis, and architecture patterns.
PythonDjangoI can develop and operate distributed systems with concurrency, parallelism, and database and networking fundamentals.
PostgreSQLKubernetesDockerI can manage the full software lifecycle and deliver projects aligned with business and technical requirements.
CI/CDI can apply systems programming (C, Java, Python, Rust), operating systems, and computer architecture to production systems.
JavaPythonRustI can work across the stack from low-level systems to high-level applications using architecture, operating systems, and multiple languages.
PythonTypeScriptI can reason about algorithmic complexity and choose appropriate data structures and algorithms for performance and maintainability.
AlgorithmsI can write and review technical specifications and documentation grounded in formal methods and engineering practice.
Technical DocumentationI can use testing, refactoring, and design principles to identify and reduce technical debt and improve quality.
Unit TestingIntegration TestingI can apply mathematical and statistical foundations (calculus, algebra, discrete math) to modeling and problem-solving in software systems.
Applied StatisticsI can design and train deep learning models using frameworks such as Keras, TensorFlow, and PyTorch for computer vision, NLP, and sequence modeling.
MLOpsTensorFlowKerasI can build agentic AI systems and custom agents (e.g. with LangChain) for code assistance, tool use, and autonomous workflows, similar to Cursor-style behavior.
AI AgentsLLMsRAG
2019
Business Administration
UNLaMI built a fintech company from scratch as my final project: business plan, financial projections, regulatory considerations, and go-to-market strategy.
Financial ManagementForecastingI can manage people and teams: hiring, performance, and coordination aligned with organizational goals.
Project ManagementTeam ManagementI can lead financial administration: budgeting, forecasting, cost allocation, and economic and financial modeling for planning and reporting.
BudgetingForecastingI can align technical roadmaps with business goals using project and capital administration from the degree.
Project ManagementI can analyze financial statements, manage risk, and support decision-making with quantitative and process-optimization tools.
Risk ManagementFinancial ReportingI can apply marketing strategies, market research, and positioning to support product and growth decisions in tech and startups.
Market ResearchI can interpret contracts, compliance requirements, and regulatory constraints in business and product contexts.
ComplianceI can use applied statistics and quantitative methods for forecasting, reporting, and data-driven decisions.
Applied StatisticsI can optimize processes and allocate resources across teams or projects using cost and operations management.
Process OptimizationI can contribute to audit, internal controls, and financial reporting in tech and startup environments.
AuditingFinancial Reporting
2012
Certificate in Advanced English
Cambridge UniversityI can communicate fluently with US-based teams and stakeholders in meetings, async channels, and written documentation.
Stakeholder CommunicationI can lead or contribute to technical discussions, code reviews, sprint ceremonies, and RFCs in English with clarity and precision.
Technical DocumentationI can write clear technical documentation, incident reports, and proposals for distributed and cross-functional audiences.
Technical DocumentationI can collaborate effectively with Product, Design, and non-engineering partners in English without language barriers.
Stakeholder CommunicationI can present to customers or partners and handle customer-facing communication when required by the role.
Stakeholder Communication
2008
First Certificate in English
Cambridge UniversityI can follow technical discussions, stakeholder meetings, and standups in English and contribute to day-to-day collaboration.
Remote CollaborationI can participate in daily standups, retros, and cross-team conversations in English with confidence at B2 level.
Remote CollaborationI can write professional emails, tickets, and short documentation in English for remote and distributed teams.
Technical DocumentationI can engage with English-speaking clients or support when needed and understand requirements and feedback.
Stakeholder CommunicationI can provide a strong, permanent foundation for further advancement to C1 (CAE) for more complex professional communication.
Remote CollaborationCertifications



2026
Model Context Protocol: Advanced Topics
AnthropicModel Context Protocol (MCP)AnthropicAI AgentsLLMs

2025
Google Data Engineer and Cloud Architect Guide
UdemyGoogle Cloud Platform (GCP)Data EngineeringBigQueryDataflow (Apache Beam)Pub/SubCloud Storage (GCS)Cloud SQLDataprocStreaming DataCloud RunCloud FunctionsVPC

2024
AWS Solutions Architect Professional
AWSAWS EC2ELBVPCElastic BeanstalkRDSDMSMGNAWS S3AWS DynamoDBAWS LambdaAWS SQSAWS SNSAWS API GatewayAWS IAMAWS Cost ExplorerAWS OrganizationsAWS ElasticCacheAWS CloudFrontAWS Lambda@EdgeAWS Direct ConnectAWS Private LinkAWS DataSyncAWS SnowballAWS Snowcone
2024
Data Science: Deep Learning and Neural Networks in Python
UdemyDeep LearningNeural NetworksPythonPyTorchTensorFlowKerasCNNsModel Training
2024
Natural Language Processing with Deep Learning in Python
UdemyNatural Language Processing (NLP)Deep LearningTransformersLLMsHugging FaceEmbeddingsText ClassificationNamed Entity Recognition (NER)Vector SearchPython

2024
CyberSecurity
UdemySecurityPrivacyRisk AssesmentEncryptionVulnerabilitiesHash FunctionsDigital CertificatesSSLHTTPSFirewallUpdatesPrivilegesSocial EngineeringSecurity DomainsMAC AddressPhysical IsolationVirtualization
2023
Networking Fundamentals
UdemyTCP/IP ModelIP AddressingIP SubnettingIPv4IPv6DomainsTCPUDPWiresharkVLANSpanning TreePacket TracerRouting AlgorithmsStatic RoutingDHCPDNSVLSMNTPSNMPSyslogSecurityTroubleshootingVoIPACLsNATOSPFIPSecWi-Fi
2022
Data Structures & Algorithms
UdemyRecursionTime ComplexitySpace ComplexityArraysSetsMatricesLinked ListsDouble Linked ListsCircular Linked ListsStacksQueuesBinary TreeBinary HeapHash TablesBubble SortSelection SortInsertion SortBucket SortMerge SortQuick SortHeap SortGraphsShortest PathDisjoint SetGreedy AlgorithmsDivide and ConquerBell Dynamic Programming
2022
Docker & Kubernetes
UdemyDockerDockerfileContainer LifecycleLogsVolumesNetworkingDocker-ComposeDockerHubAWS ECRCI/CDAWS Elastic BeanstalkAWS ECSKubernetesEKS
2021
Deep Learning Specialization
DeepLearning.AINeural NetworksBinary ClassificationLogistic RegressionGradient DescentDerivativesNumPyKerasTensorFlowBias vs VarianceRegularizationDropoutVanishing GradientExploding GradientAdam OptimizationXavier InitializationComputer VisionEdge DetectionPaddingStridesConvolutional LayerPooling LayerResNet ArchitectureMobileNet ArchitectureData AugmentationTransfer LearningObject DetectionBounding Box PredictionYOLO AlgorithmU-NetFace RecognitionSequence ModelsRecurrent Neural NetworksGRULSTMWord EmbeddingsGloVe Word VectorsWord2VecSentiment ClassificationBeam SearchAttention ModelSpeech RecognitionTransformers
2021
Database Architecture, Scale and NoSQL with Elasticsearch
University of MichiganCourseraACID vs BASEElasticsearchMappingsAnalyzersNormalizersTasksAliasesSettingsShardsReplicas
2021
Graph Theory
UdemyGraph AlgorithmsAlgorithmsData StructuresShortest-Path AlgorithmsDijkstra's AlgorithmGraph AnalyticsGraph DatabasesPathfindingCombinatorial OptimizationGraph Theory

2021
Introduction to Quantum Computing Course
IBM QuantumQuantum MechanicsQiskitQuantum AlgorithmsIBM Quantum ExperienceLinear AlgebraCalculusGeometry
2021
AWS Fundamentals Specialization
Amazon Web ServicesCourseraAWSIAMVPCEC2S3RDSDynamoDBLambdaCloudWatchSecurityRoute 53CloudTrail
2021
Big Data: Hadoop and Spark
UdemyHadoopHDFSMap ReducePigHiveHBaseSqoopFlumeOozieScalaSparkSpark SQLKafkaSpark Streaming
2021
Master in Applied Statistics
Euroinnova Business SchoolDescriptive StatisticsStatistical distributionsIBM SPSSMaximum likelihood methodExpectation maximiatin algorithmConfidence intervalsHypothesis testingFeature engineeringLinear regression modelsBivariate regression modelsMultivariate regression modelsPolinomial regression modelsColinearityMulticolinearityLog-linear ModelsAutocorrelationF-TestOutlier detectionEconometricsBiostatisticsTime series analysisStochastic processesMarkov processesNon-parametric tests


2020
AI for Medical Diagnosis
CourseraNumPyNeural NetworksMedical Image DiagnosisMRI DataImage ClassificationImage InbalanceImage SegmentationData AugmentationBinary Cross Entropy Loss FunctionSensitivitySpecificityPrevalncePPVNPVConfusion MatrixROC CurveCNN ArchitectureU-Net

2020
Neural Networks & Deep Learning
CourseraLogistic RegressionCost FunctionsActivation FunctionsGradient DescentVectorizationParameters Initialization
2020
Modern Deep Learning in Python
Deep Learning AINeural NetworkGradient DescentStochastic Gradient DescentNesterov MomentumGrid SearchVanishing GradientsExploding GradientsTensorflowTheanoKerasPyTorchEnsemblesDropoutBatch Normalization
2020
Recommender System and Deep Learning in Python
UdemyUser-User Collaborative FilteringItem-Item Collaborative FilteringMatrix FactorizationSingle Value DecompositionPageRankKerasTensorFlowAutoencodersResidual LearningApache Spark
2020
AWS Lambda & Serverless Architecture
UdemyServerless FrameworkAWS LambdaJWT TokensAuthorizersAWS API GatewayAWS Code CommitAWS Code PipelineAWS Code BuildAWS DynamoDBSwaggerCD/CI
2019
ReactJS & Redux
UdemyReactFormsComponentsHooksAxiosreact-routerreact-reduxredux-sagaAuthenticationFirebaseUnit TestingWebpackNext.jsAnimations

2019
Machine Learning with Python
UdemyData ProcessingLinear RegressionPolynomial RegressionSVRDecision TreesRandom ForestK-ClusteringHierarchical ClusteringK-Fold Cross ValidationParameter TuningGrid Search
2019
Natural Language Processing with Python
UdemyPythonnltkSpaCyTokenizationStemmingLemmatizationStop WordsPOS TaggingNERText ClassificationScikit-LearnConfusion MatrixSemantic AnalysisSntiment AnalysisWord VectorizationTopic ModelingText SynthesisChat BotPyPDF2Regular Expressions
2015
IBM IT Specialist in Services and Infrastructure
IBMWeb DevelopmentPerlDatasource IntegrationSQLServer AdministrationNetworkingDatabase AdministrationStorage AdministrationVirtualizationIBM AIXRHELOracle SolarisSANNASGFPS2LVMWebSphereLDAPSSO
2010
IBM AIX 5 Basics (Q1313) & Administration (Q1314)
IBMFile SystemPermissionsProcessesServicesShell ScriptingArchivingcronInstallationVirtualizationDevicesLVMRun LevelsSoftware ManagementCertifications
2026 · Claude with Amazon Bedrock · Anthropic
2026 · Introduction to agent skills · Anthropic
2026 · Model Context Protocol: Advanced Topics · Anthropic
2026 · Claude 101 · Anthropic
2025 · Google Data Engineer and Cloud Architect Guide · Udemy
2024 · Rust Programming · Udemy
2024 · AWS Solutions Architect Professional · AWS
2024 · Data Science: Deep Learning and Neural Networks in Python · Udemy
2024 · Natural Language Processing with Deep Learning in Python · Udemy
2024 · The Complete Node.js Developer Course · Udemy
2024 · CyberSecurity · Udemy
2023 · Networking Fundamentals · Udemy
2022 · Data Structures & Algorithms · Udemy
2022 · Docker & Kubernetes · Udemy
2021 · Deep Learning Specialization · DeepLearning.AI
2021 · Database Architecture, Scale and NoSQL with Elasticsearch · University of Michigan · Coursera
2021 · Graph Theory · Udemy
2021 · Configuring and Deploying VPCs with Multiple Subnets · AWS
2021 · Introduction to Quantum Computing Course · IBM Quantum
2021 · AWS Fundamentals Specialization · Amazon Web Services · Coursera
2021 · Big Data: Hadoop and Spark · Udemy
2021 · Master in Applied Statistics · Euroinnova Business School
2021 · Full Stack development with Django · Udemy
2021 · SQL: Data Reporting & Analysis · LinkedIn
2020 · AI for Medical Diagnosis · Coursera
2020 · Deep Learning with Keras · CGFIUBA
2020 · Neural Networks & Deep Learning · Coursera
2020 · Modern Deep Learning in Python · Deep Learning AI
2020 · Recommender System and Deep Learning in Python · Udemy
2020 · AWS Lambda & Serverless Architecture · Udemy
2019 · ReactJS & Redux · Udemy
2019 · Web Scraping with Python · Udemy
2019 · Machine Learning with Python · Udemy
2019 · Natural Language Processing with Python · Udemy
2015 · IBM IT Specialist in Services and Infrastructure · IBM
2010 · IBM AIX 5 Basics (Q1313) & Administration (Q1314) · IBM
AI Agents
This project delivers an AI-powered virtual assistant built with LangChain and RAG, enabling context-aware conversations and document analysis powered by OpenAI's GPT models. It allows users to query documents and hold coherent, context-rich dialogues with intelligent retrieval and generation capabilities.
LangChainPythonRAGOpenAI
This project is a React-based single page application, styled using TailwindCSS, that allows users to explore and analyze character interactions in Project Gutenberg e-books. The application leverages a Language Learning Model (LLM) to process the text of e-books and visually represent character interactions through an interactive network graph. The application is deployed on AWS using the AWS Cloud Development Kit (CDK), which automates the setup of AWS Lambda for backend processing and API Gateway for handling requests efficiently.
ReactNode.jsTypeScriptOpenAI APIReact FlowAWS
This project is a tool that helps you create SQL queries using AI technology. It has a web interface that works like Cursor, making it easy to use. The system uses two different AI agents that work together: one agent talks with you to understand what you need, and another agent creates the actual SQL code.
GPTAI AgentReactTailwindSQL
This project represents a cutting-edge integration of LangChain and Large Language Models (LLMs) to enhance the processing and comprehension of web search results, aiming to refine and reconstruct truncated information for improved clarity and user engagement. By leveraging advanced NLP techniques and custom tool development, we have successfully created an intelligent agent capable of consulting previous messages, conducting web searches, and presenting human-readable summaries without the common ellipsis truncation.
Machine LearningLLMLangChainPythonStreamlitOpenAI APILLMs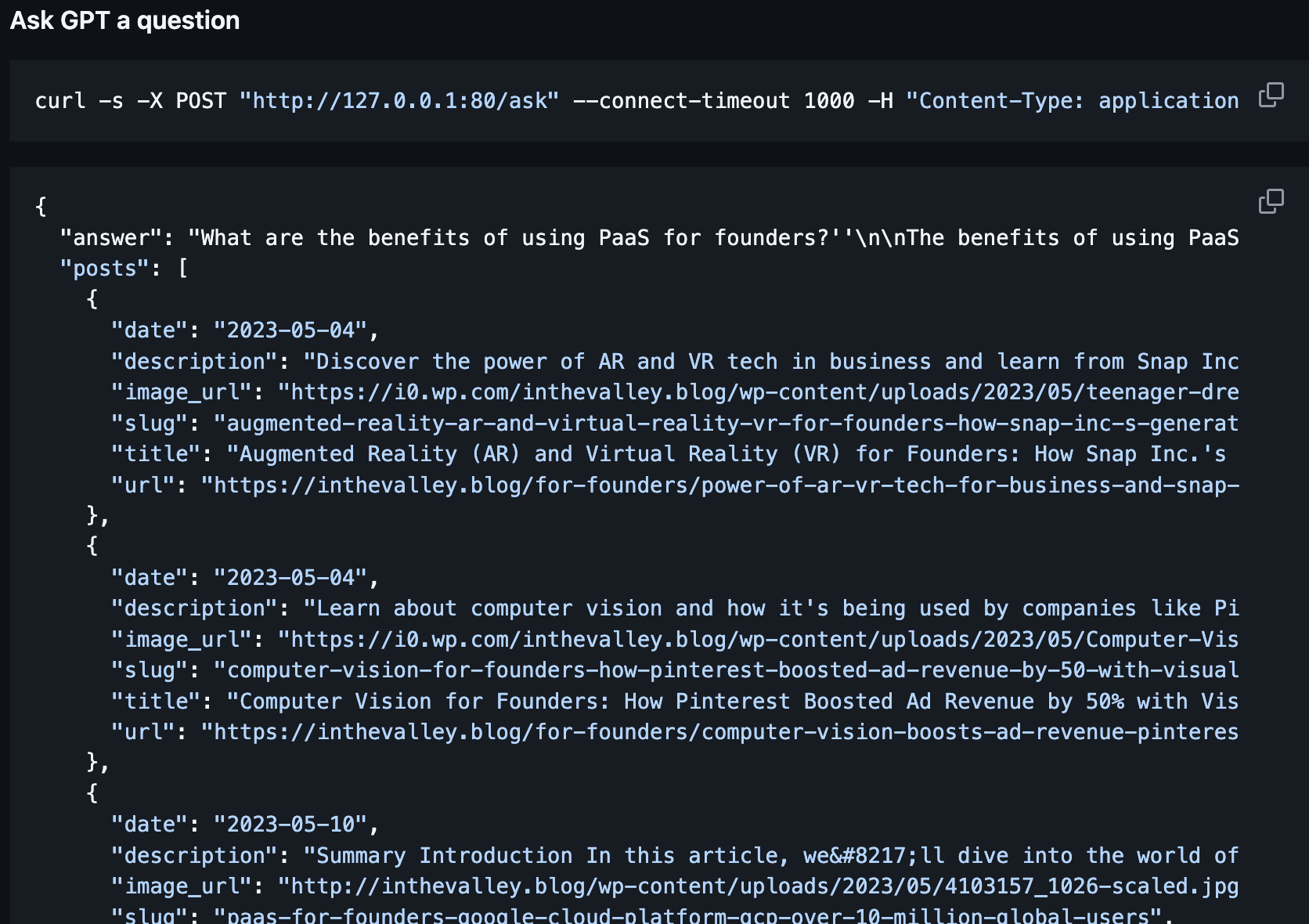
This project focuses on leveraging the powerful combination of the GPT API, Elasticsearch, and SpaCy to implement a specialized chatbot capable of context injection. The chatbot's primary objective is to ingest and analyze data from a specific WordPress blog, providing relevant and contextual responses to user queries.
PythonOpenAI APILLMsRAG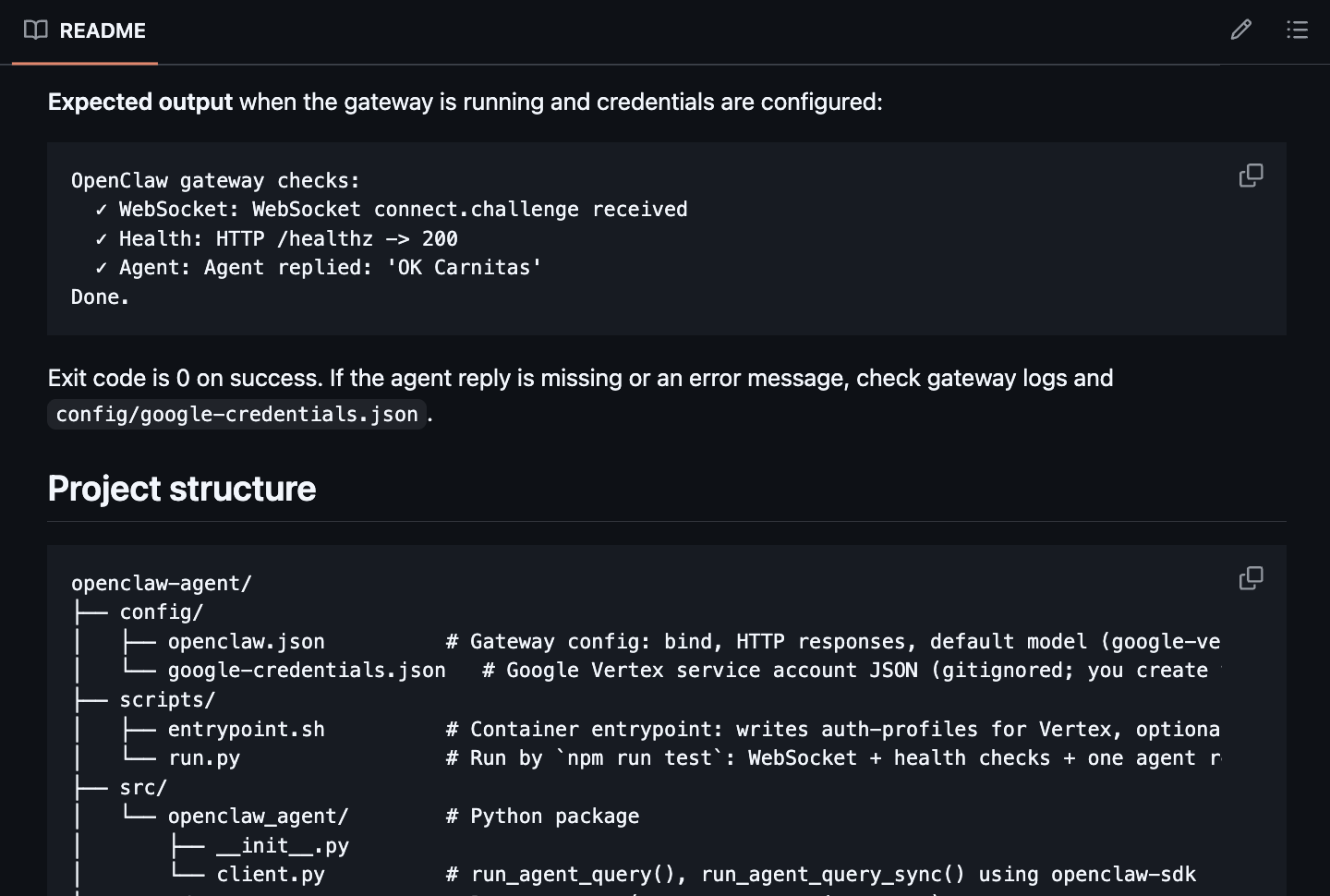
This project is an autonomous AI agent client that uses the OpenClaw SDK to connect to a local OpenClaw gateway over WebSocket for agent interactions, including messaging channels such as WhatsApp and Telegram. It includes a Docker-based gateway and integration with Google Vertex (Gemini) for scalable, cloud-backed agent workflows.
AI AgentsLLMsPythonDockerDeep Learning
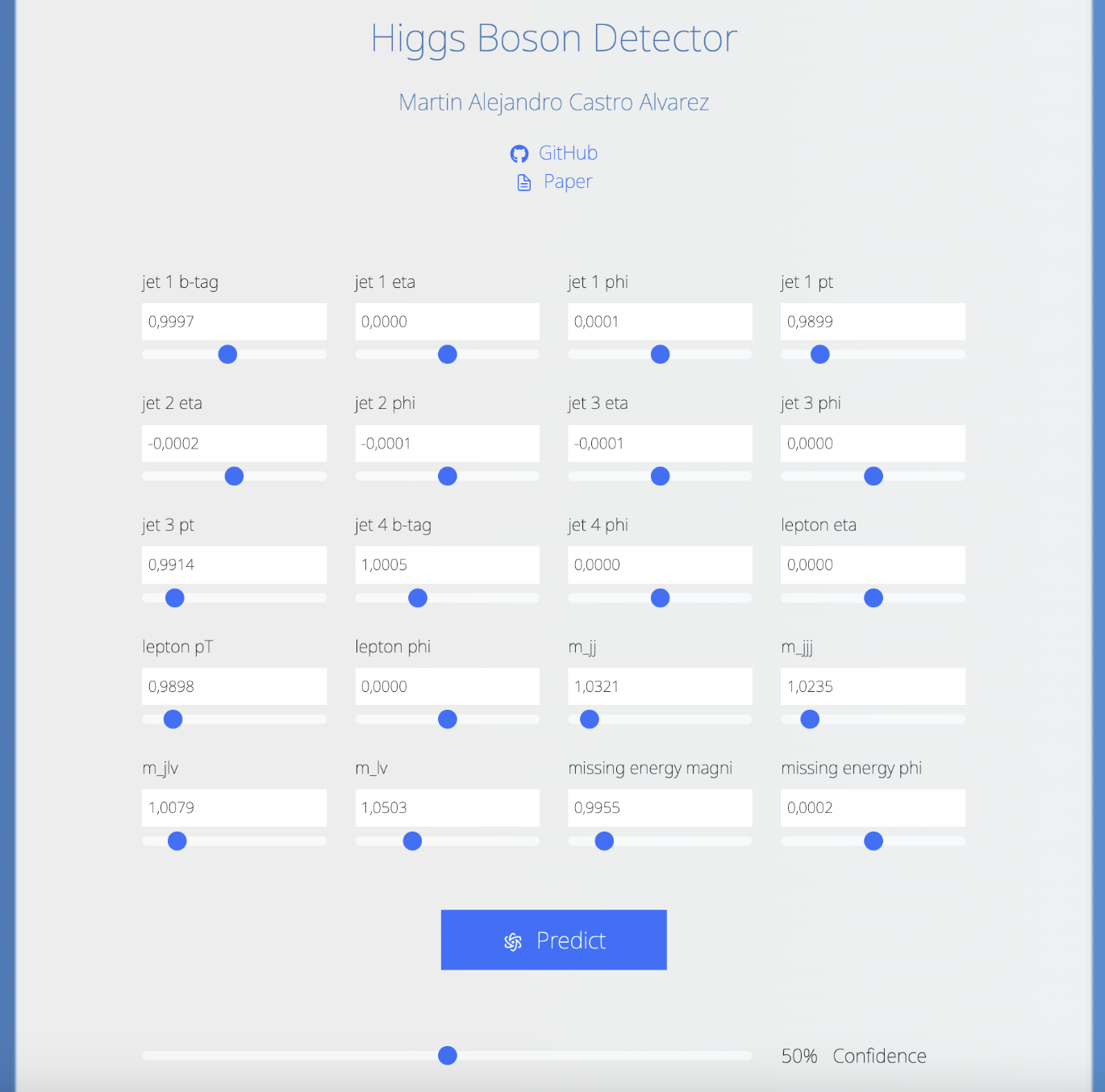
This project develops advanced machine learning models to detect Higgs boson signals in particle physics data, utilizing scikit-learn for feature engineering and statistical analysis. It includes comprehensive data visualization with Matplotlib and Seaborn to explore and validate model performance on high-energy physics datasets.
Scikit-LearnPythonJupyter NotebookMatplotlibSeabornNumPySciPy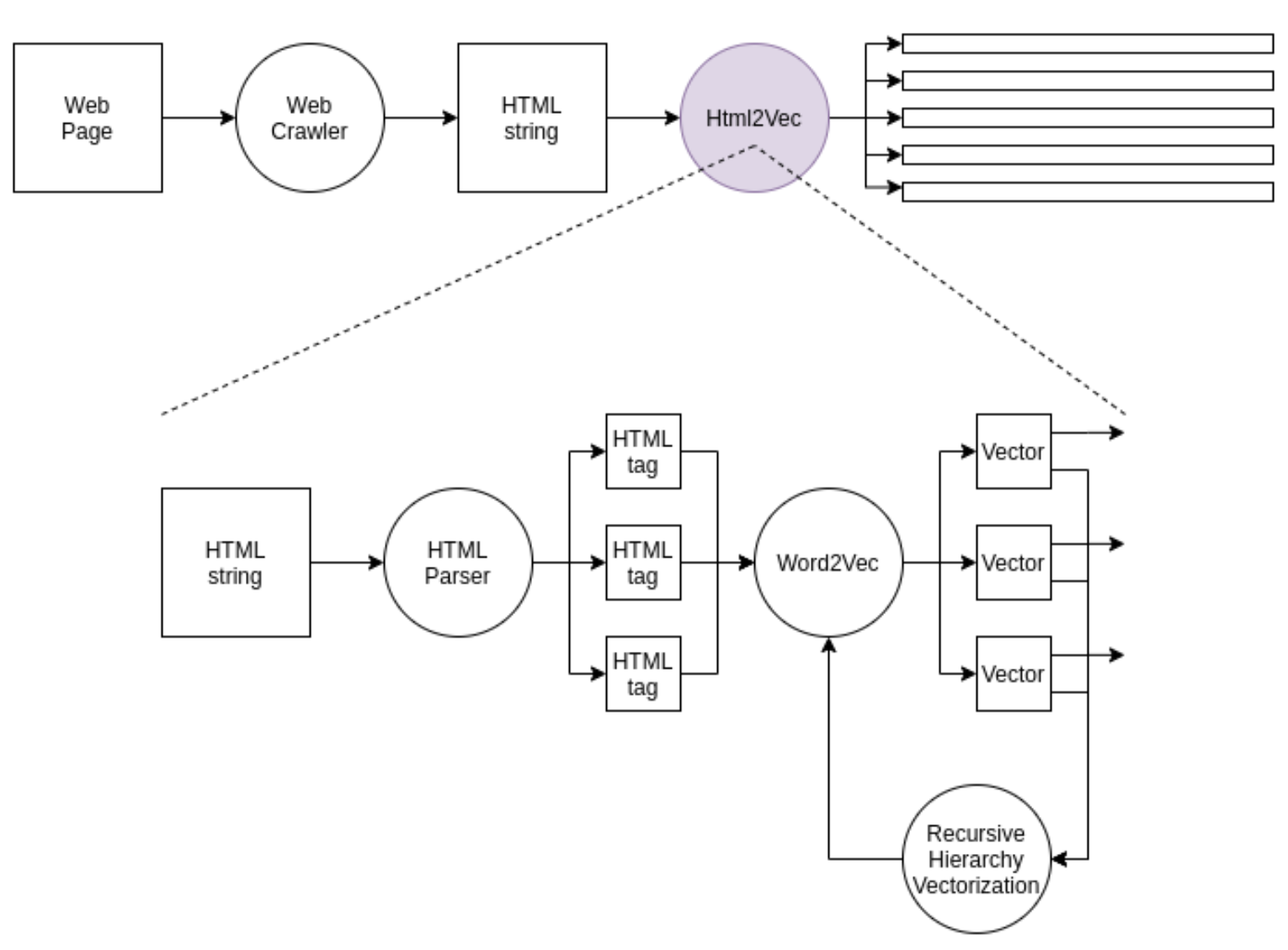
The project involved developing an algorithm to convert HTML documents into vectorized objects suitable for use with neural networks. The algorithm used a combination of techniques, including HTML parsing, natural language processing, and dimensionality reduction. The resulting vectors could then be used as inputs for machine learning models to perform tasks such as document classification or information retrieval. The implementation was done in Python, using libraries such as BeautifulSoup and Scikit-learn.
PythonEmbeddingsNumPySciPySpaCy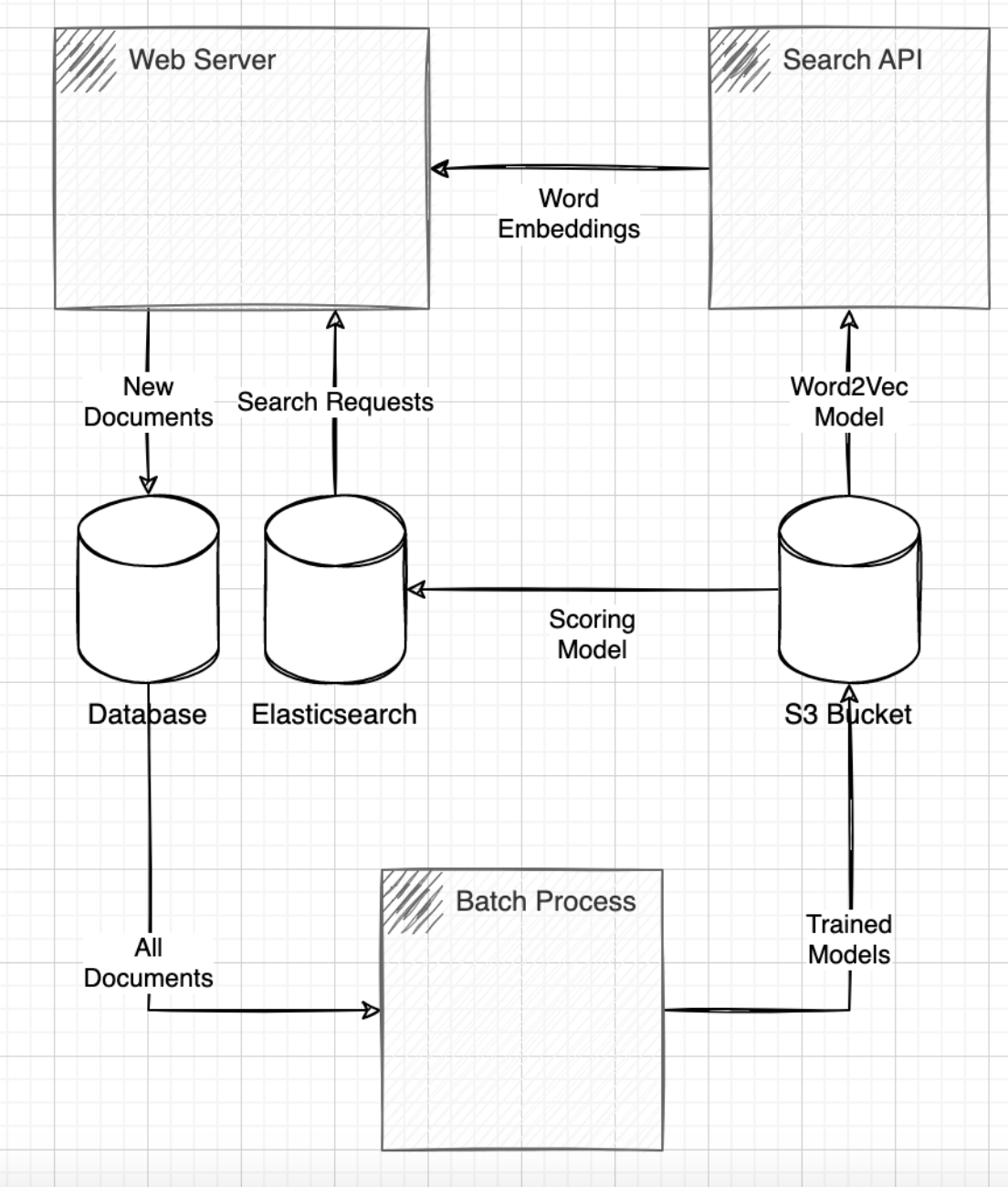
This project builds a semantic search engine that combines Word Embeddings (GloVe) with Elasticsearch, enabling efficient text similarity search and content recommendation. It leverages Keras and Gensim for embedding generation and integrates with Elasticsearch for scalable indexing and retrieval of document collections.
PythonWord EmbeddingsGloVeElasticsearchKerasNumPy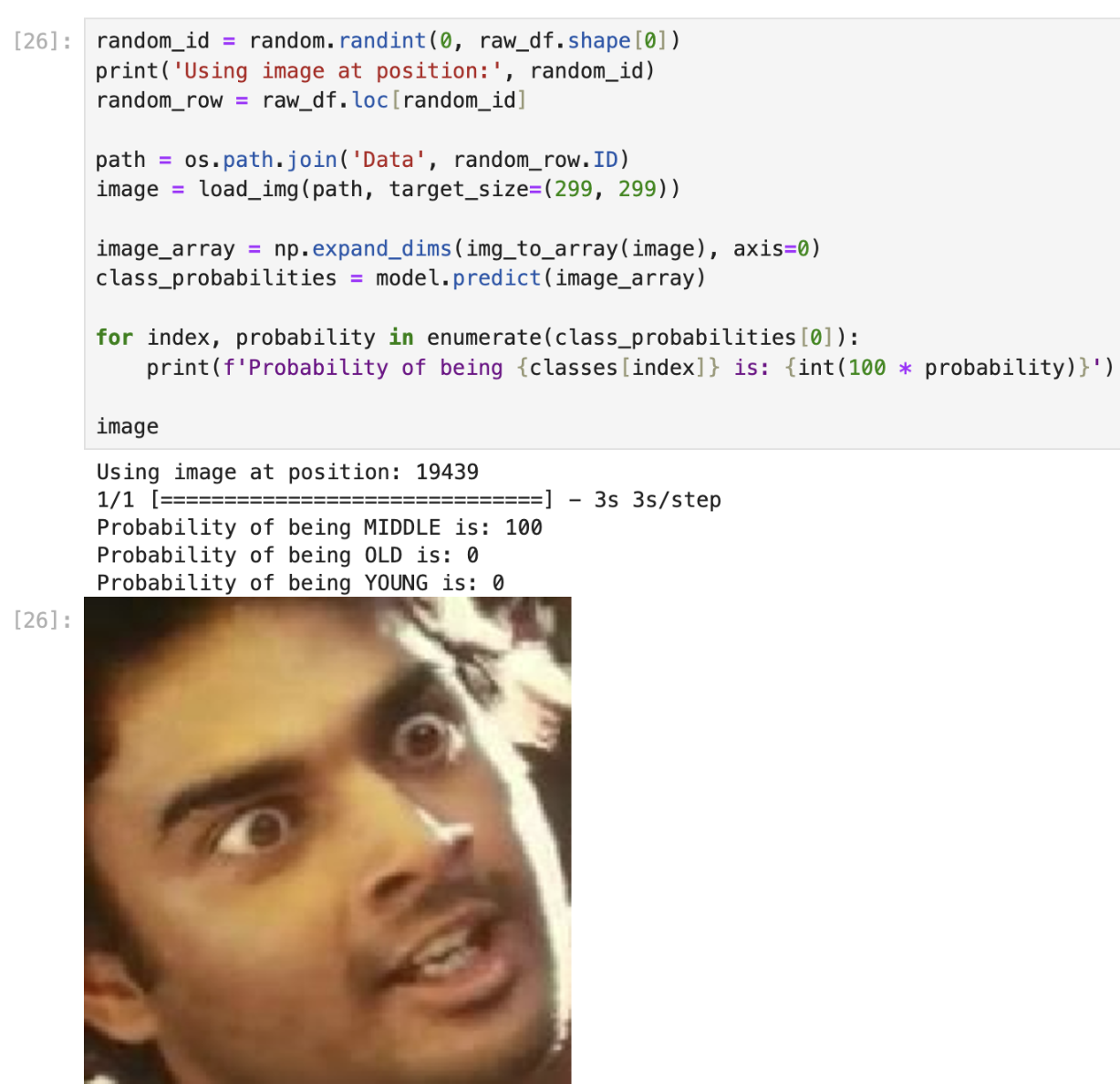
This project develops a CNN-based age detection system using Keras, implementing transfer learning for accurate facial age estimation from images. It includes comprehensive data preprocessing pipelines and is designed for robust performance on real-world face datasets.
PythonCNNNumPyKerasPandas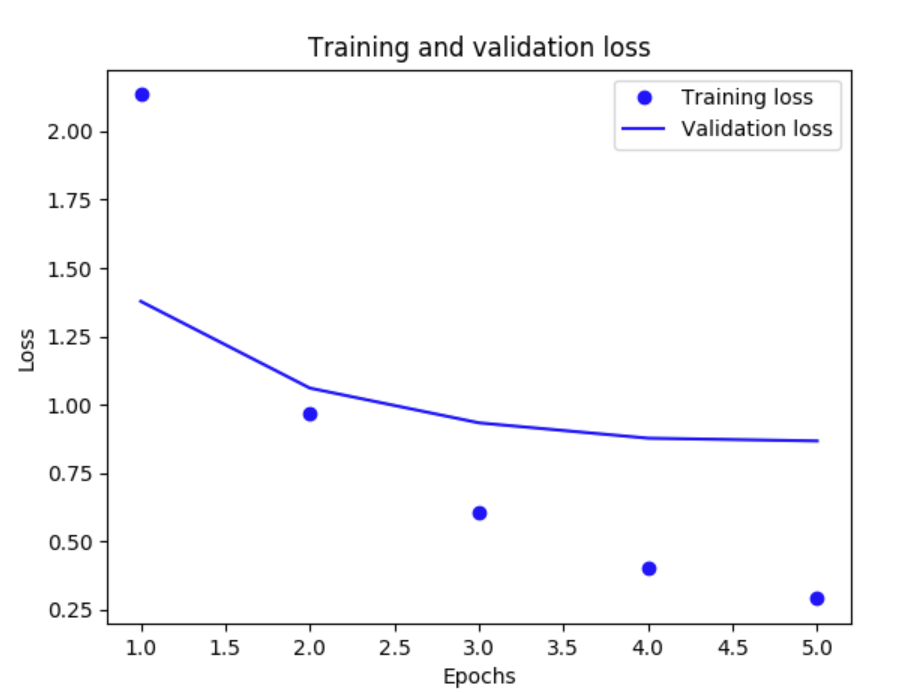
Implementation of a Neural Network to classify text with Python and Keras. Python Keras NLP Neural Networks Text Classification Topic Modeling Matplotlib SpaCy POS tagging Lemmatization.
PythonKeras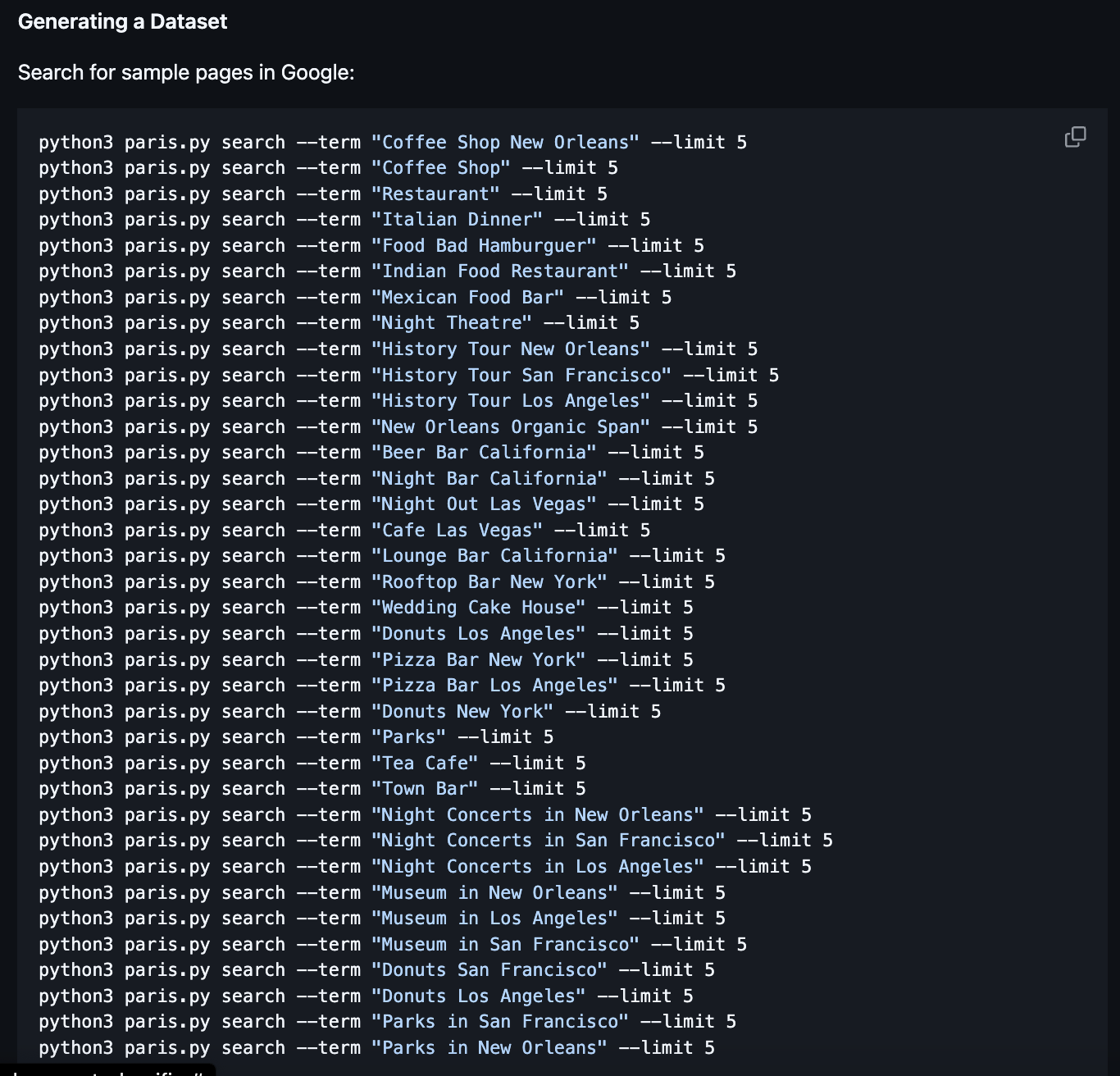
The project involved building a document classifier using a neural network implemented with Keras. Data was scraped using the Newspaper3k library and the Google Search API to obtain a corpus of articles related to the topic. The articles were preprocessed using spaCy for POS tagging and lemmatization. The model was trained on this data and evaluated using various performance metrics. AsyncIO and aiohttp were used for asynchronous data retrieval and web scraping, respectively.
PythonKeras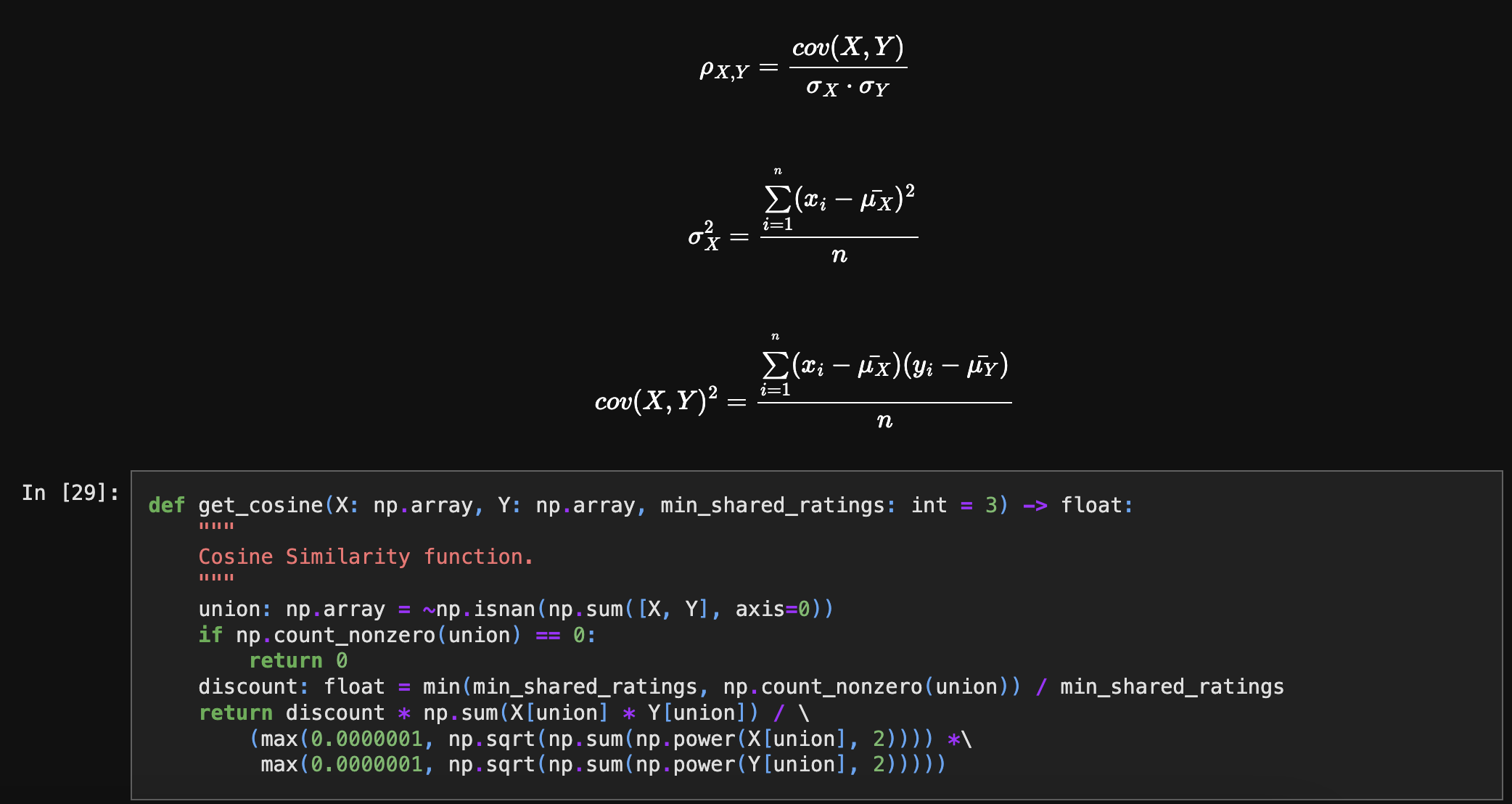
This project creates a fully serverless personalized recommendation engine using AWS Lambda, NumPy, and Algolia, delivering low-latency suggestions through collaborative filtering and novelty and diversity algorithms. It is designed for scalable, cost-effective recommendation APIs without dedicated servers.
PythonNumPyMatplotlib
The project utilizes Keras and Deep Learning to perform link prediction in a heterogenous information network, enabling accurate predictions between entities of different types.
PythonKeras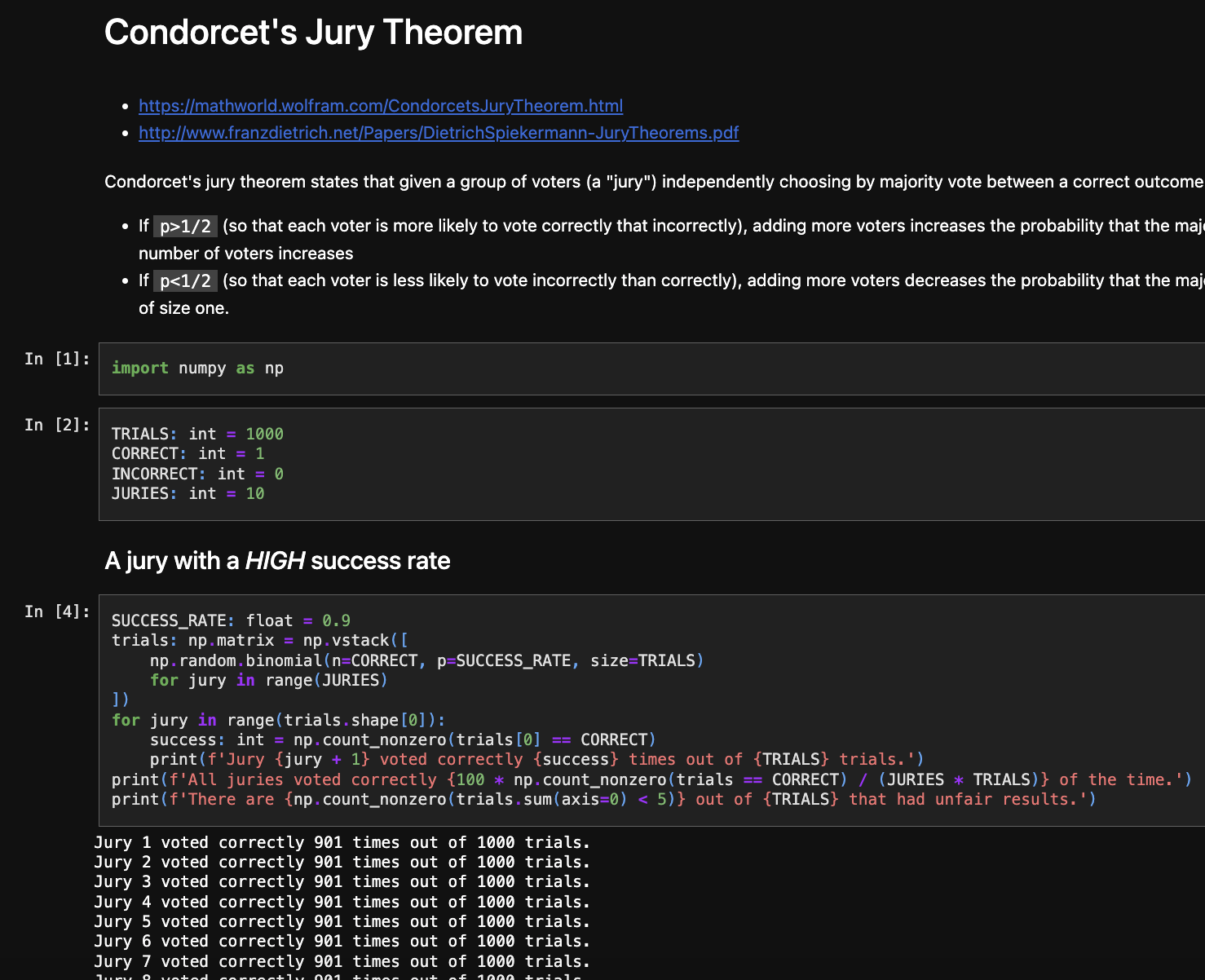
This project implements advanced deep learning algorithms in Python, focusing on efficient numerical computing with NumPy and scientific computing with SciPy. It demonstrates core concepts and optimizations used in building and training neural networks and related models.
PythonSciPyKerasPandasMatplotlib
This project engineers a supply chain optimization system using Python and NumPy, implementing efficient algorithms for logistics and resource allocation. It addresses routing, inventory, and allocation problems with numerical and optimization techniques suitable for real-world constraints.
PythonNumPy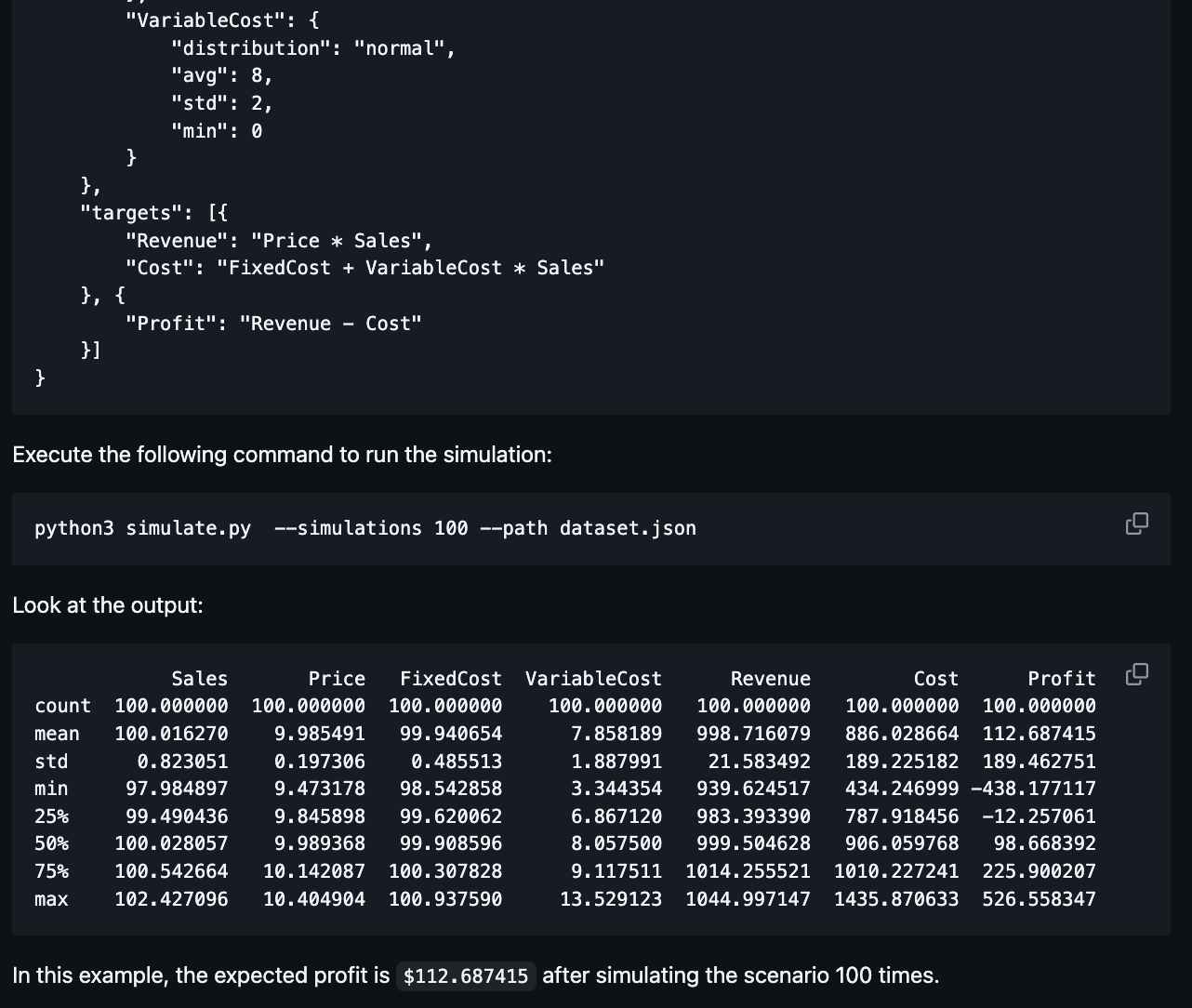
This project builds a sophisticated Monte Carlo simulation framework using Python and SciPy, enabling complex probabilistic modeling and statistical analysis. It supports scenario generation, sampling, and result aggregation for applications in finance, science, and engineering.
PythonSciPy
This project aims to utilize the powerful scipy library to perform statistical analysis on various distributions and identify the ones that best fit a given dataset. The project will involve analyzing and visualizing the results to gain insights into the underlying distribution of the data.
PythonSciPyMatplotlib
This project implements genetic algorithms with a focus on algorithmic complexity analysis, enabling efficient optimization and problem-solving strategies. It uses mutation, crossover, and selection to evolve solutions and includes analysis of performance and scalability.
PythonGenetic AlgorithmsAlgorithmic ComplexityComputer Vision
This project demonstrates advanced OpenGL rendering techniques by implementing a real-time 3D scene with multiple camera perspectives. It features three distinct geometric objects (a cube, a pyramid, and a prism) rendered with Phong-Blinn lighting and dynamic shading. The application showcases both a primary and a secondary camera, with the secondary camera's view displayed as a floating minimap overlay within the main window. The project includes custom framebuffer management, real-time object animation, and interactive window resizing, all built using modern OpenGL (Core Profile 3.3), GLFW, GLEW, and GLM for matrix and vector operations.
OpenGLC++3D Rendering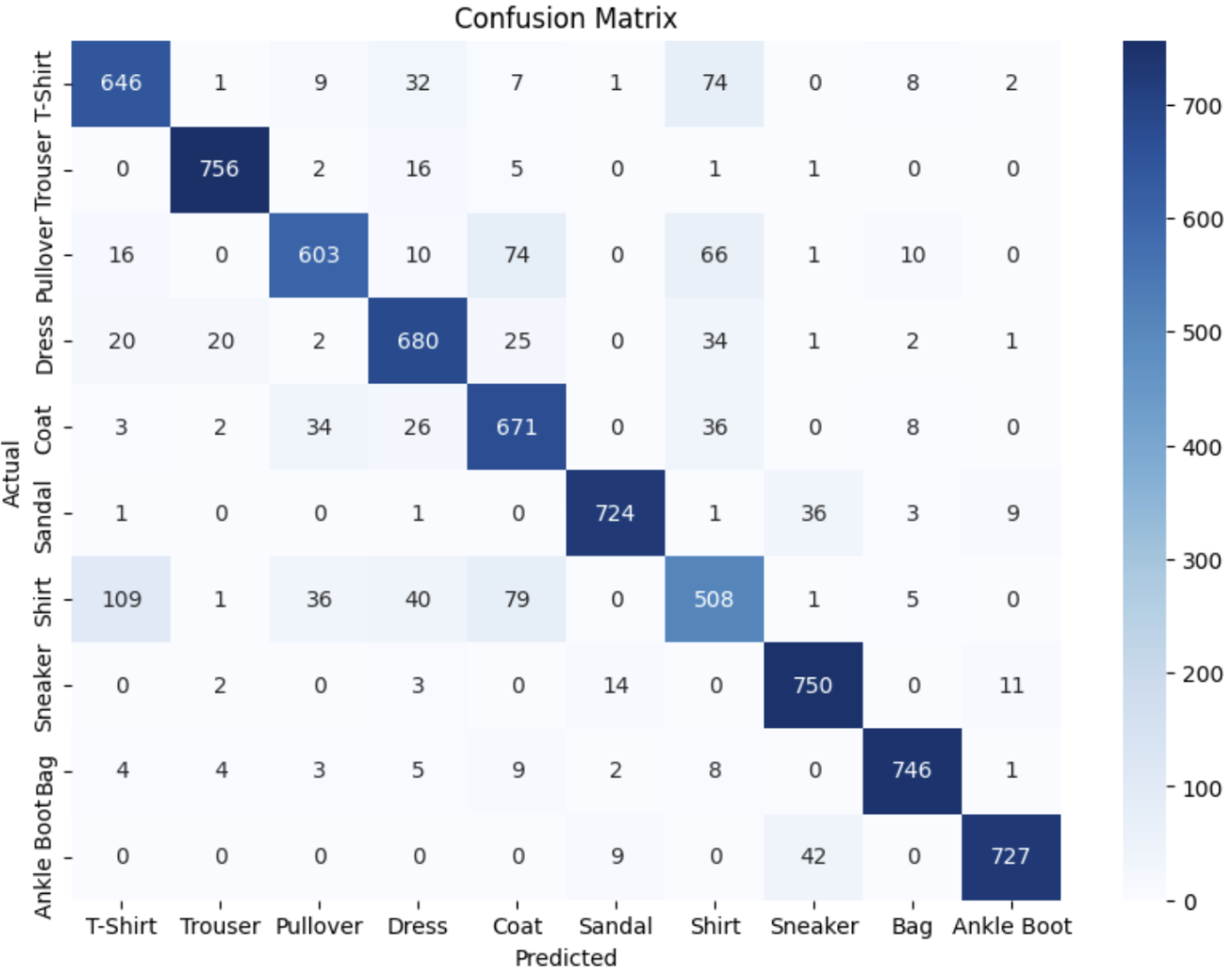
This project involves developing a deep learning model for classifying different types of apparel from images, such as T-shirts, trousers, pullovers, dresses, and more. Using a pre-trained Vision Transformer (ViT) as the base model, the project enhances it with additional layers to improve classification accuracy. The model is trained with techniques like data augmentation, batch normalization, and dropout to reduce overfitting and enhance performance. The training process includes handling class imbalances by sampling more instances of underrepresented classes, and the optimizer is fine-tuned to focus on these new layers.
PyTorchPythonJupyter NotebookMatplotlibSeabornNumPy
The project involved building a model for text classification by first conducting topic modeling using the Natural Language Toolkit (nltk) in Python. After identifying the most relevant topics, a neural network was implemented using the Keras library to classify text into those topics. The text was preprocessed using SpaCy for part-of-speech tagging and lemmatization. The accuracy of the model was visualized using Matplotlib. The project also included a comparative analysis of the performance of the neural network model against other classification models.
PythonTensorFlowKeras
The program uses MoviePy to manipulate video files, OpenCV2 to perform image processing, and NumPy to manipulate arrays of video data. The project involves complex algorithms for transforming video frames, including blending, resizing, and overlaying videos. The movie generator is highly customizable, allowing users to adjust settings such as the video duration, frame rate, and output format.
PythonNumPyOpenCV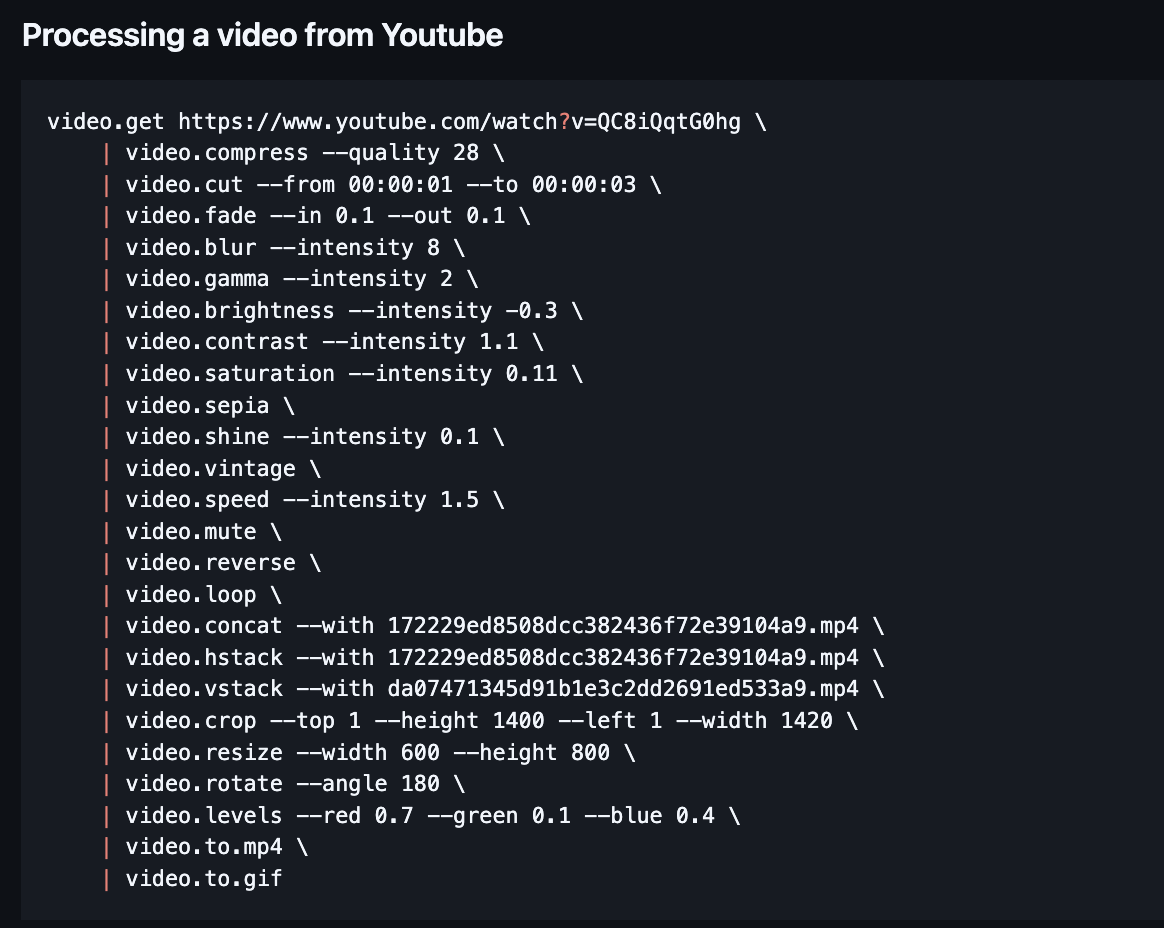
This project builds a video processing pipeline using FFMPEG, implementing efficient media conversion and manipulation through shell scripting. It automates encoding, decoding, format conversion, and batch processing of video and audio files from the command line.
FFMPEGShell ScriptingOpenCVData Engineering
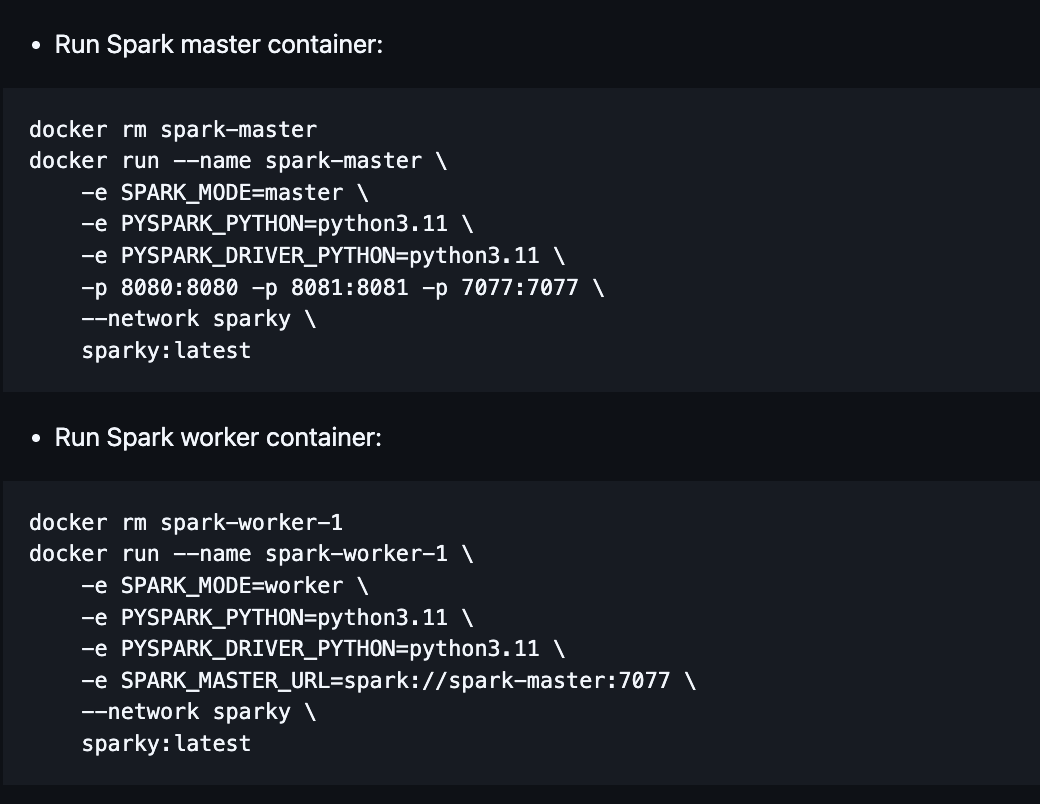
This GitHub project demonstrates the innovative integration of PySpark within Docker containers, illustrating a scalable and efficient approach to processing large datasets in distributed computing environments. By leveraging Docker's virtualization capabilities alongside PySpark's powerful data processing engine, the project offers a blueprint for building and deploying scalable data analytics applications. It showcases how to encapsulate PySpark applications in Docker, ensuring consistency, portability, and ease of deployment across different environments.
PythonApache SparkDockerPySpark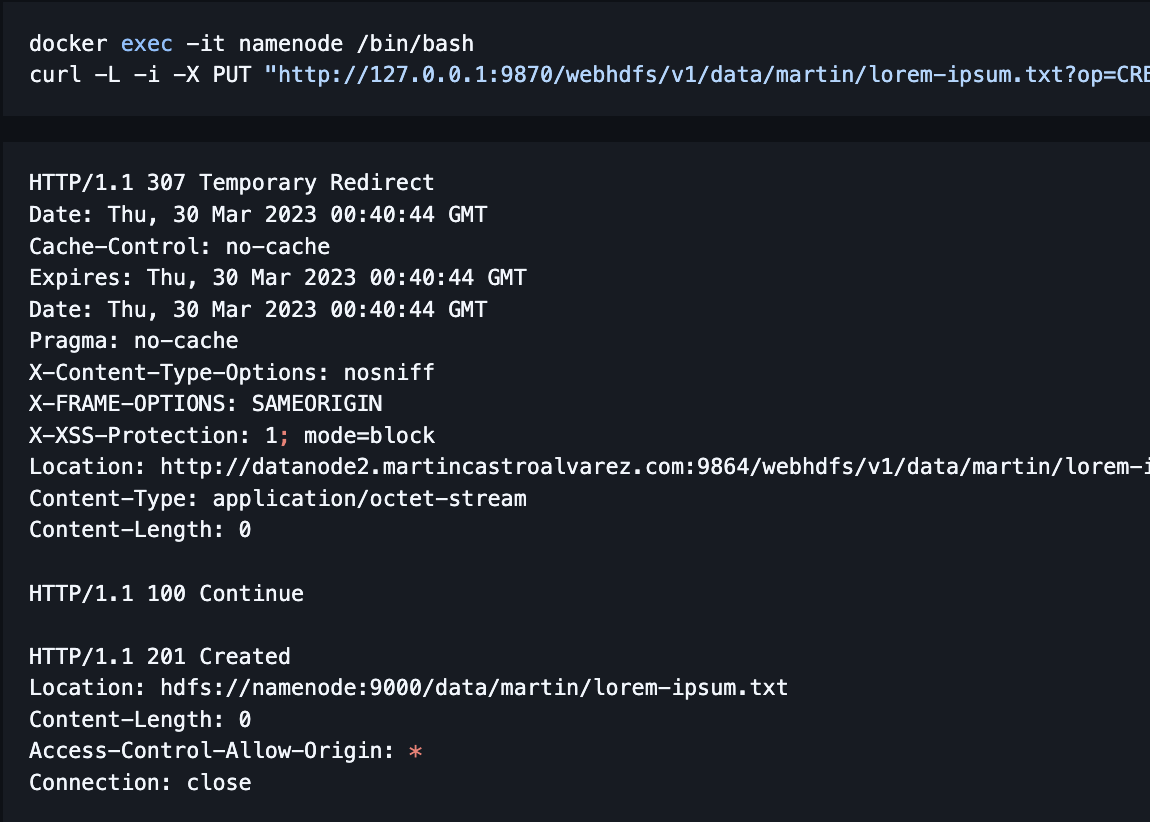
The project involved implementing a Hive server using Docker Compose, which reads and writes data to HDFS. The project also included using the Hive CLI, web interface, and Python PyHive library to interact with the Hive server. The goal was to demonstrate the versatility and ease of use of Hive and Docker Compose in setting up and managing a data processing pipeline with HDFS.
PythonApache HadoopApache HiveDocker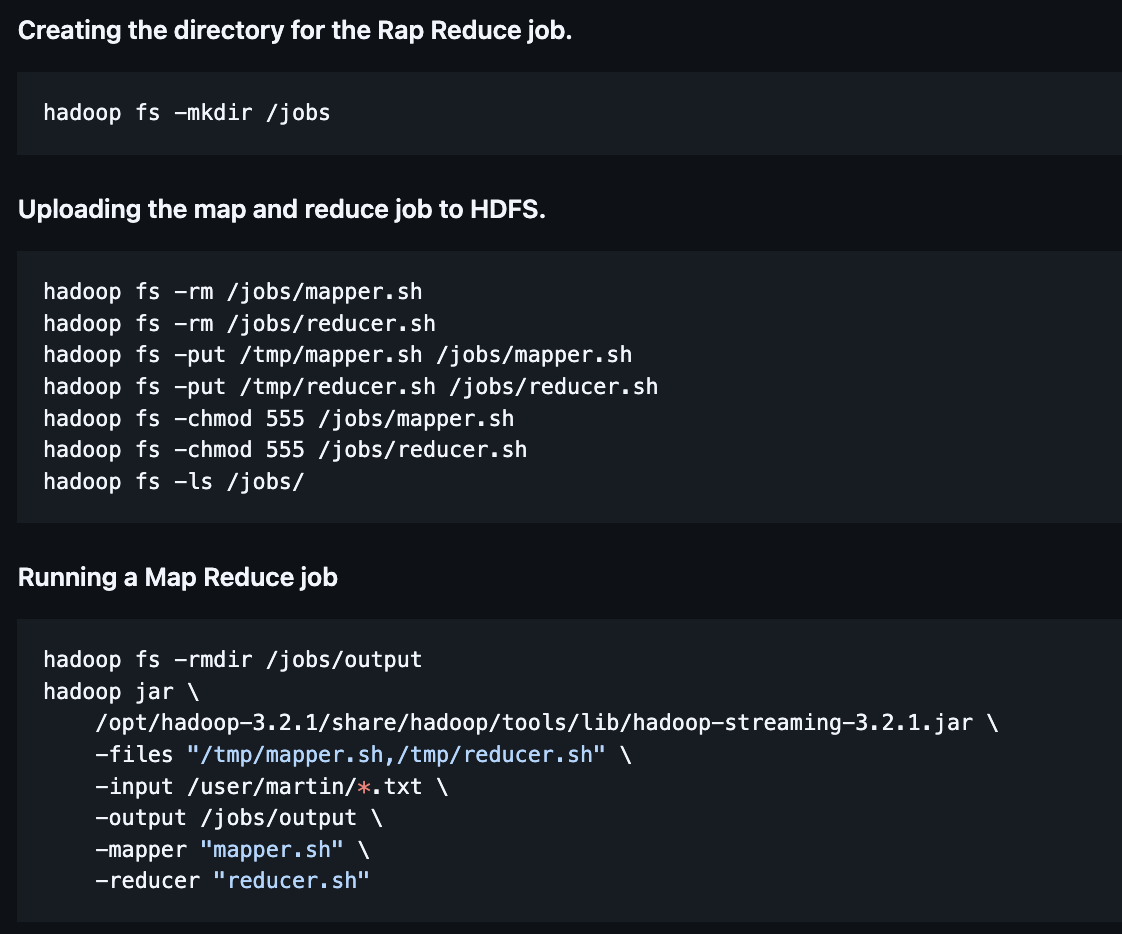
The project involved setting up a Hadoop Distributed File System (HDFS) using Docker and Docker Compose, followed by submitting a MapReduce job to the cluster. The web interface of the History Server was used to monitor the progress of the job.
PythonApache HadoopDocker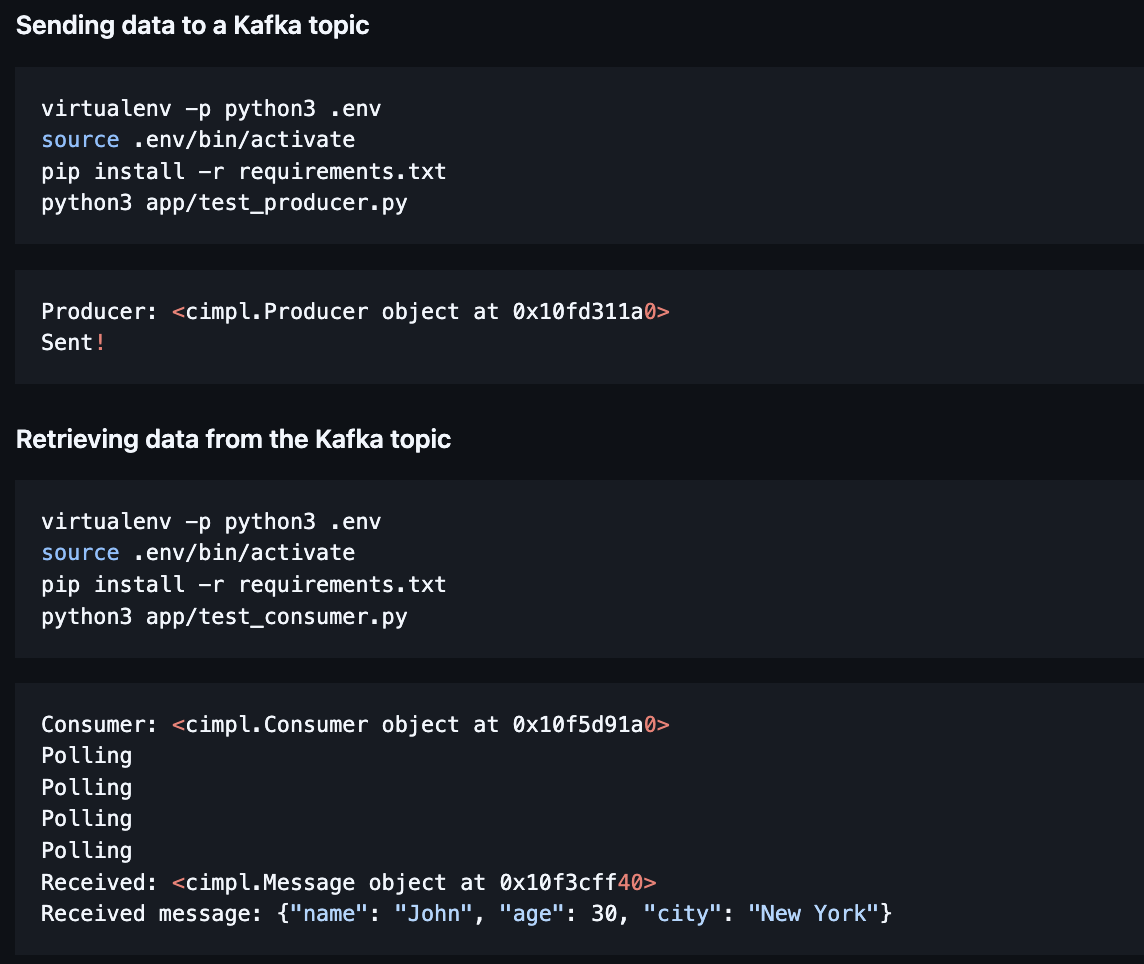
This project leverages Docker Compose to run an Hadoop Distributed File System (HDFS) cluster, along with YARN and ZooKeeper, as well as Kafka. Python is used as both the producer and consumer to send and consume data into a Kafka topic, enabling distributed data processing and storage using a familiar language and ecosystem.
PythonApache HadoopApache KafkaDocker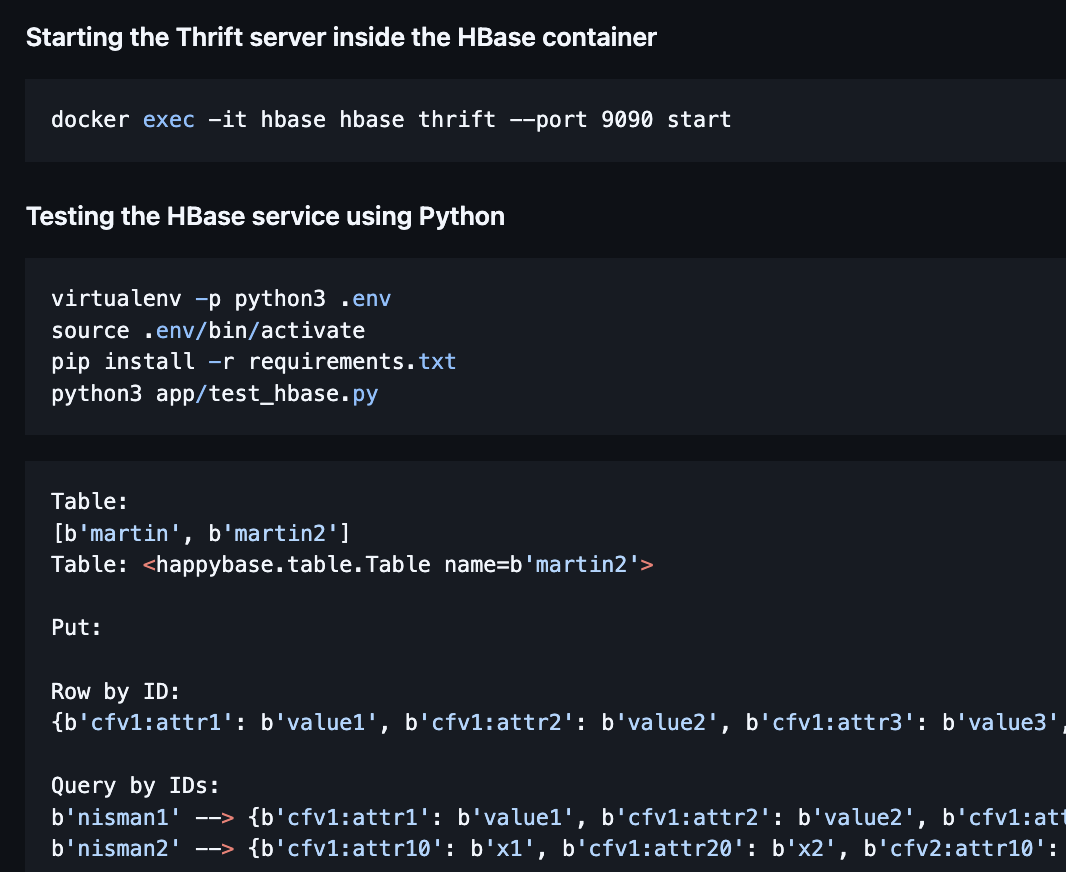
The project is a Docker-based solution for storing unstructured data in HBase with HDFS as the underlying storage system. It includes a Python client for easy data storage and retrieval, making it an ideal solution for managing large volumes of data.
PythonApache HadoopDocker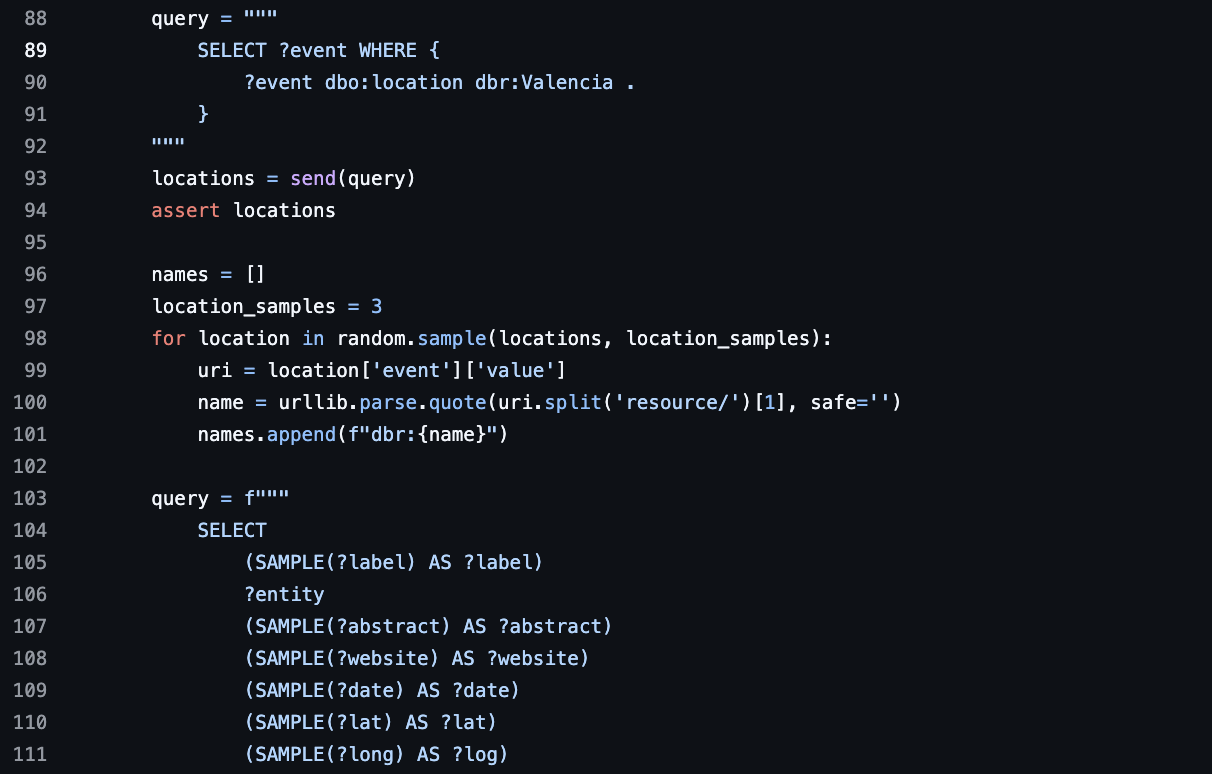
This project develops efficient SparkSQL queries for big data processing, enabling complex data transformations and analytics. It demonstrates how to structure and optimize SQL-style operations on distributed datasets using Apache Spark.
PythonSparkQL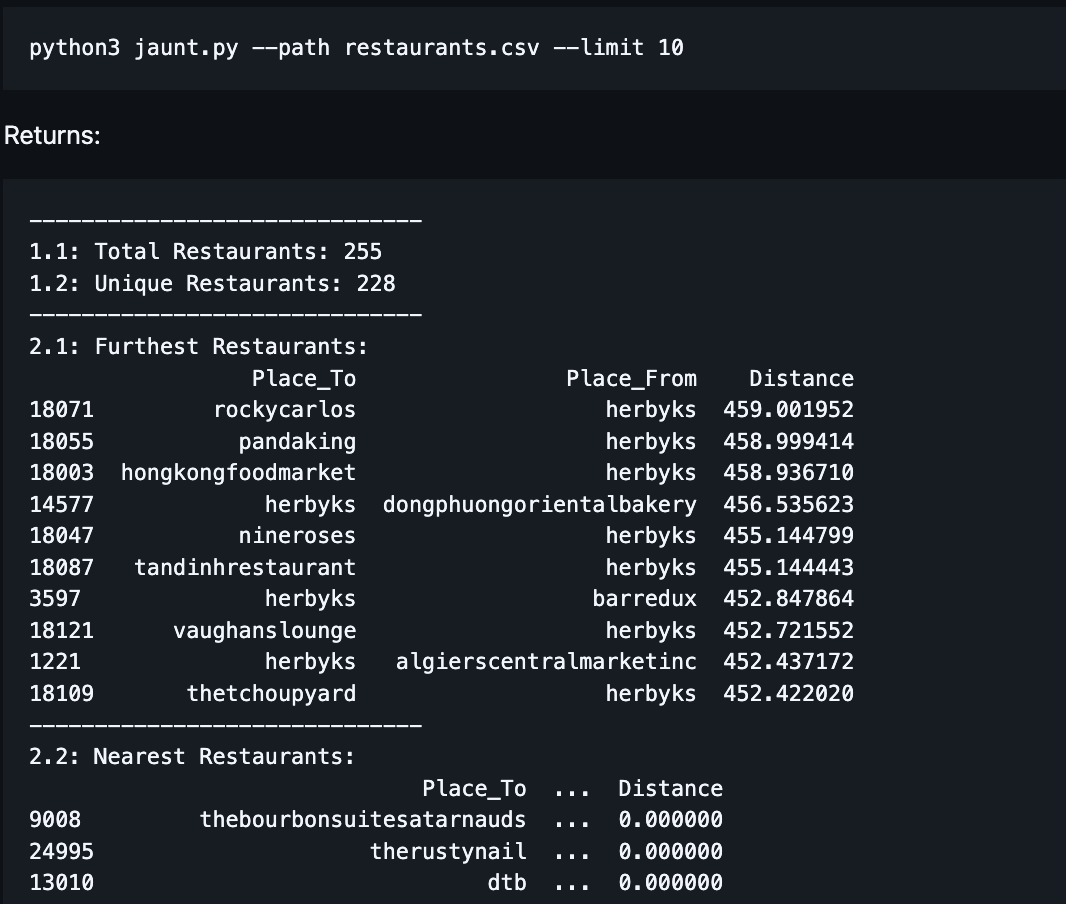
The project involved analyzing geolocation data using Pandas in Python. The data was obtained from GPS devices and contained latitude, longitude, and timestamps. The objective was to identify patterns and trends in the data to gain insights into the behavior of individuals and groups. Data cleaning techniques were applied to remove outliers and missing values. The cleaned data was then grouped and aggregated to calculate metrics such as distance traveled, speed, and duration. Visualization techniques such as heat maps and scatter plots were used to represent the data visually.
DjangoPythonPandas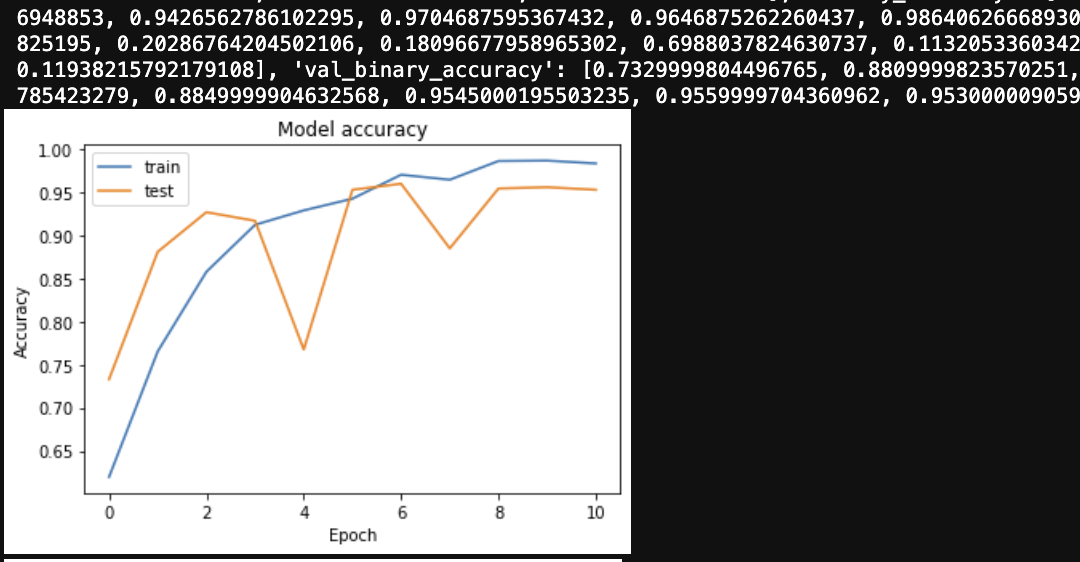
The project leverages Deep Learning algorithms to perform Record Linkage, or entity matching, by comparing and matching data from separate datasources. By utilizing Deep Learning, the project can accurately identify and link similar entities, streamlining data integration and reducing errors.
PythonPandasDevOps
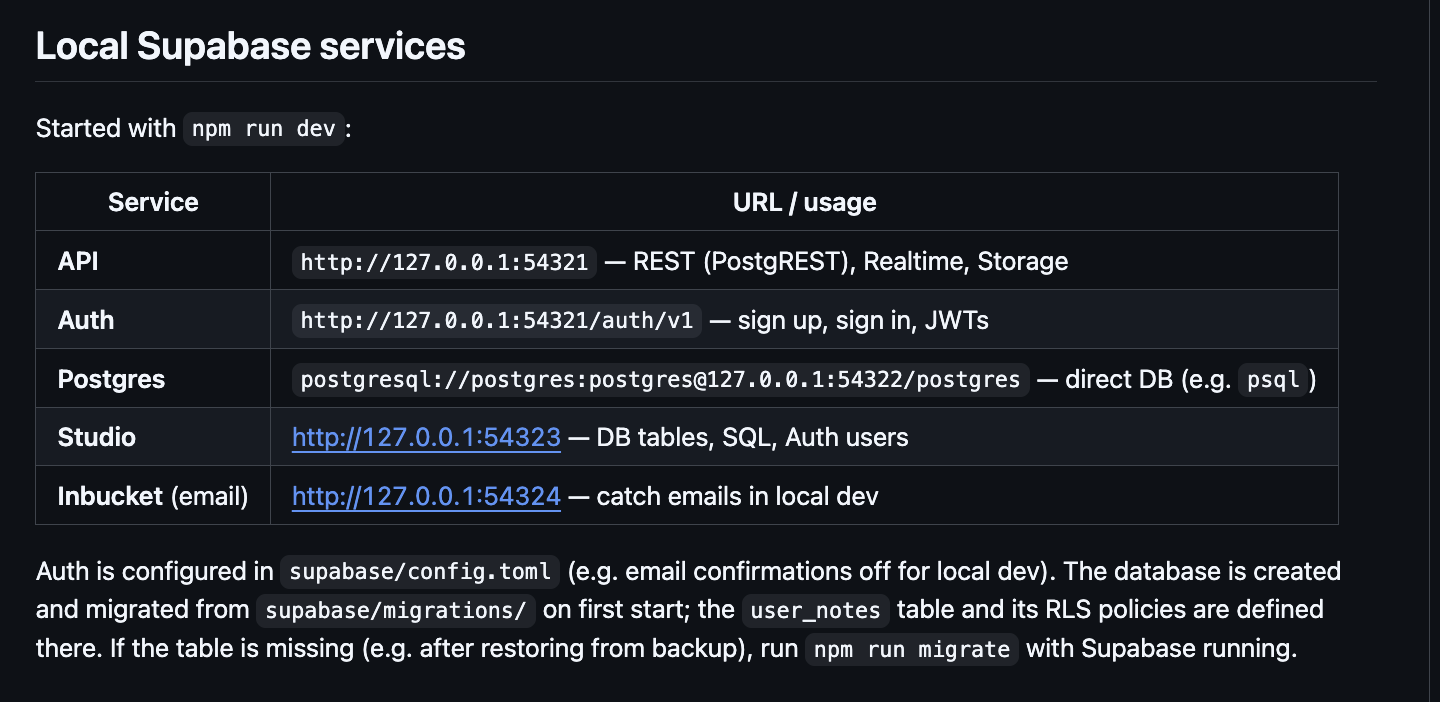
This project provides a lightweight Python interface for working with Supabase in backend workflows, enabling developers to programmatically interact with Supabase services such as the PostgreSQL database, authentication, and storage from Python applications. It is designed for engineers who want to integrate Supabase into Python-based systems, scripts, or backend services without relying on JavaScript tooling, offering a clean and minimal API for performing common operations like querying tables, inserting and updating records, and managing data pipelines.
PythonPostgreSQLDocker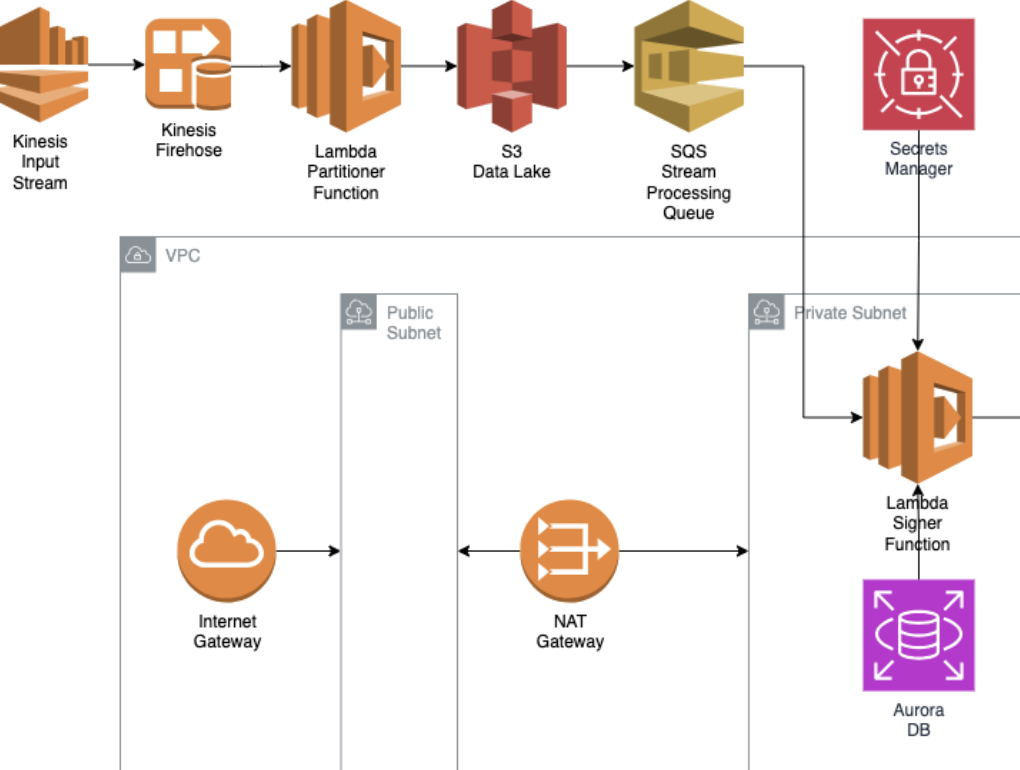
This project implements a scalable, event-driven architecture for secure transaction signing using AWS LocalStack for local emulation. It ingests high-throughput unstructured data into Kinesis, persists raw inputs to S3 for replay, and routes records through an intermediate batching stream that triggers a Lambda function. The Lambda retrieves RSA private key ARNs from Aurora Serverless, signs the batched data, and stores signed payloads in a separate S3 bucket. Built with CDK and Docker Compose, the system ensures reliable, exactly-once processing with optimized Lambda performance and modular RSA key management via AWS Secrets Manager.
AWS LocalStackStream ProcessingDockerPythonKafkaRedisMongoDBElasticsearch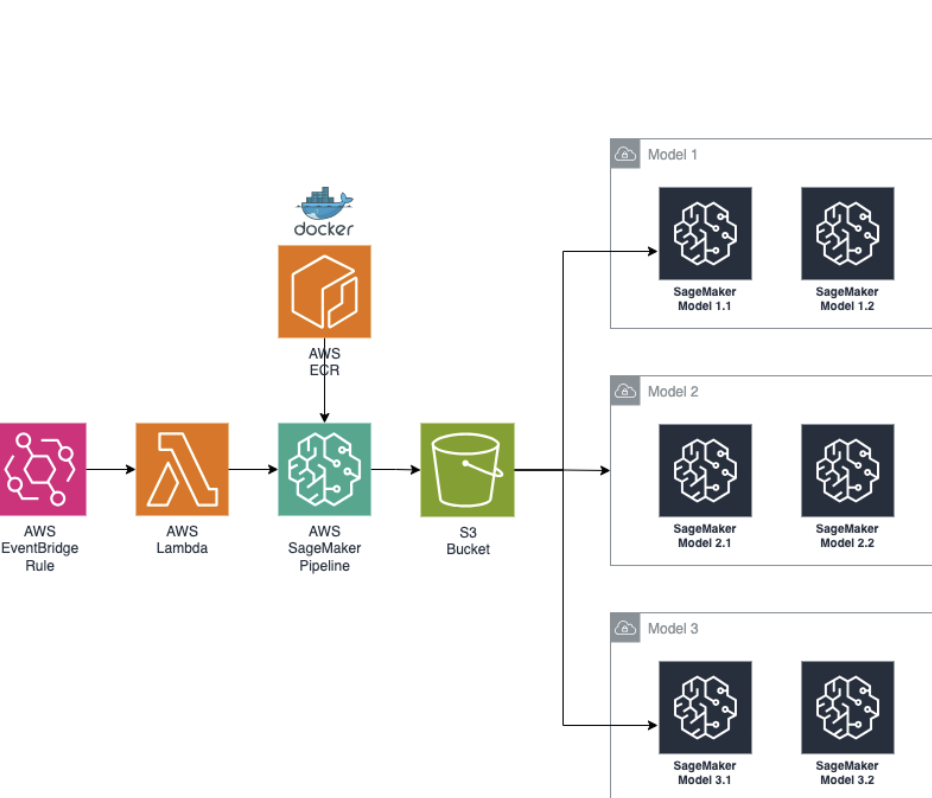
This project automates the deployment and management of multiple machine learning models using AWS services like SageMaker, Lambda, API Gateway, and EventBridge, ensuring seamless integration and scalable real-time inference.
AWS SageMakerMLOps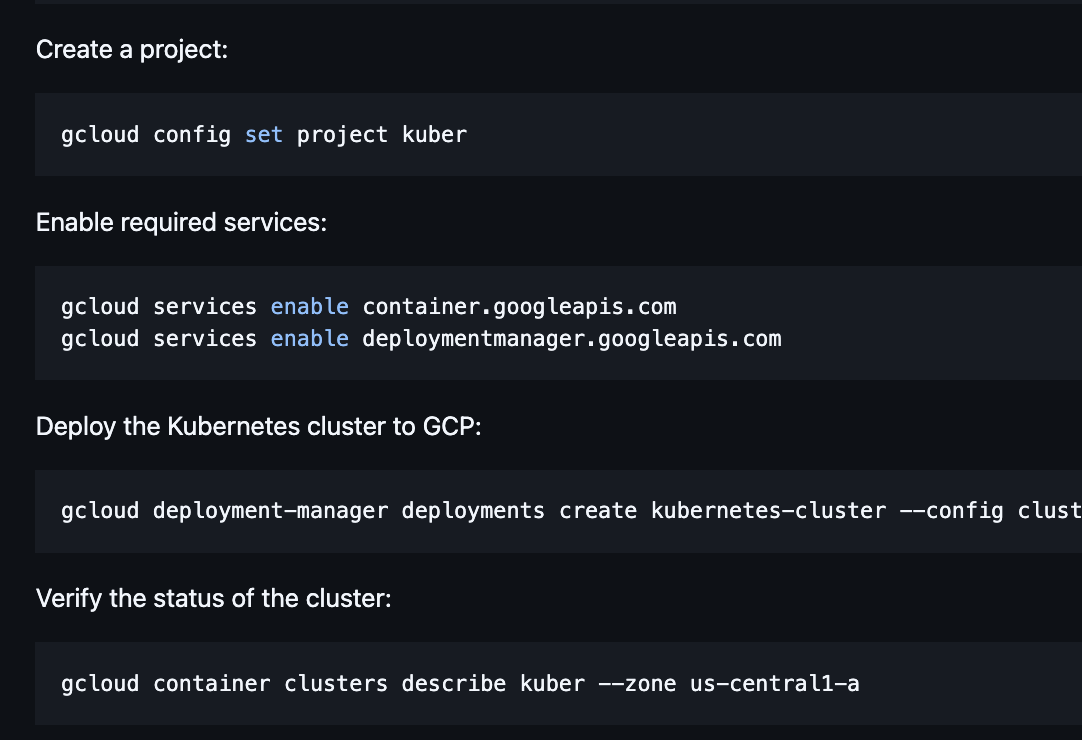
This project involved setting up a Kubernetes cluster on Google Cloud Platform using Google Cloud Deployment Manager, automating the creation and management of GCP resources. I developed YAML and Jinja templates to efficiently deploy a multi-node Kubernetes cluster, enhancing scalability and availability.
GCPKubernetes
The project utilizes Ansible in a Docker container to implement a Django application. It provides flexibility by connecting to AWS EC2 instances, allowing seamless deployment and management of the application in both local and cloud environments.
DjangoPythonAnsibleTerraformAWSDocker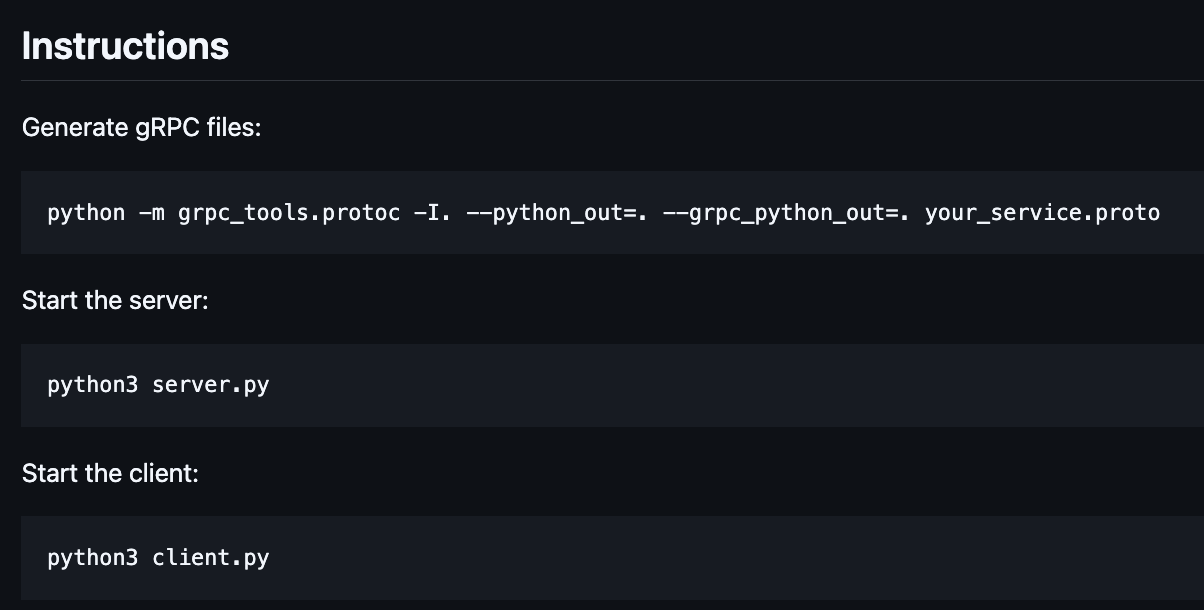
This project implements high-performance gRPC services in Python, enabling efficient microservices communication and streaming. It provides a foundation for building scalable, type-safe APIs and real-time data exchange between services using protocol buffers.
gRPCPython
The project aims to automate the deployment of a Django application using Terraform. It provisions an EC2 instance in a public subnet, installs necessary dependencies, and runs the application using Gunicorn.
DjangoPythonAWSTerraform
The project utilized Django as the primary technology stack for building a web application that was deployed on AWS Kubernetes. The application made use of Kubernetes for container orchestration and management, while Django provided a framework for building the RESTful APIs that the application relied on. The system also integrated with various AWS services such as S3 for file storage and RDS for database management.
DjangoPythonAWSKubernetes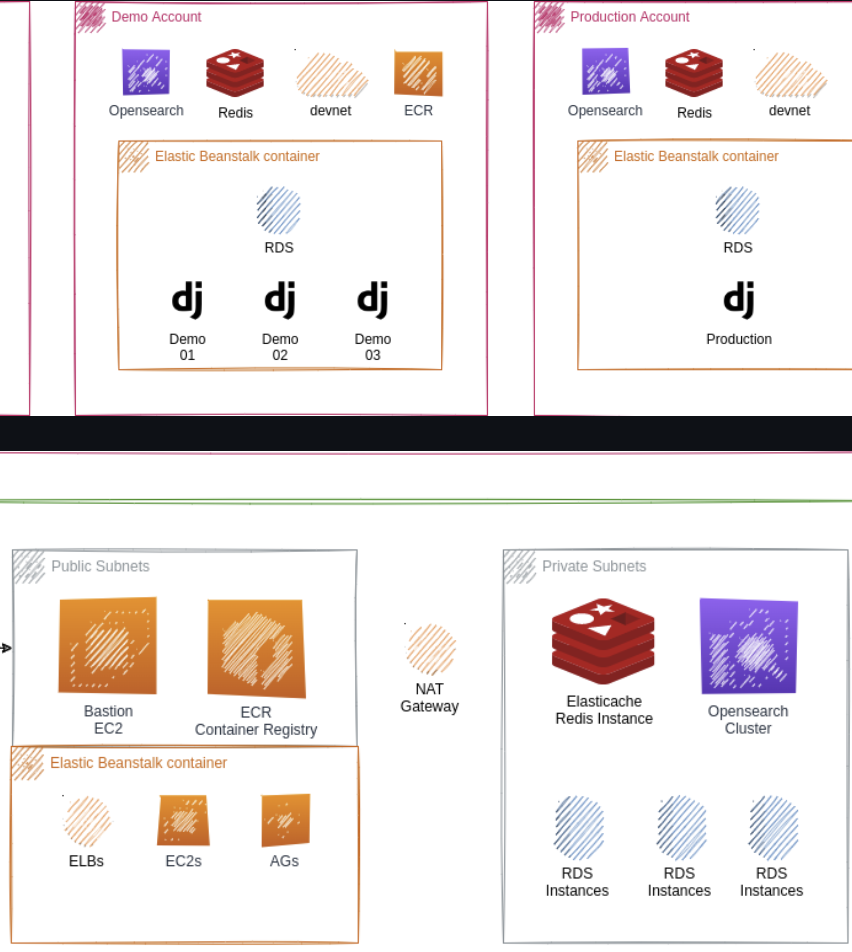
The project utilized AWS CDK to create multiple Cloud Formation stacks for deploying various AWS services. These services included an AWS network, an RDS instance, an Elasticache cluster, an OpenSearch service, and an Elastic Beanstalk instance. AWS CDK allowed for the creation of infrastructure as code, providing a more streamlined and consistent approach to deployment.
DjangoPythonAWSElasticsearchPostgreSQLRedis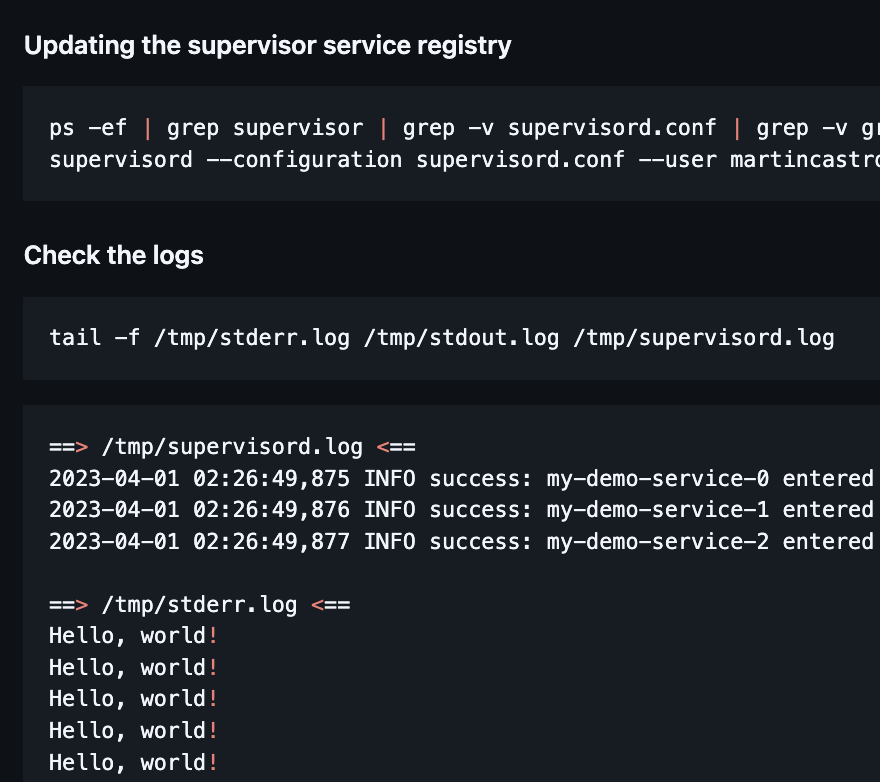
The project is a Python script managed by Supervisord, creating a daemonized service that runs continuously on Linux and automatically restarts if crashed, providing robust and reliable system operation.
LinuxSupervisorPython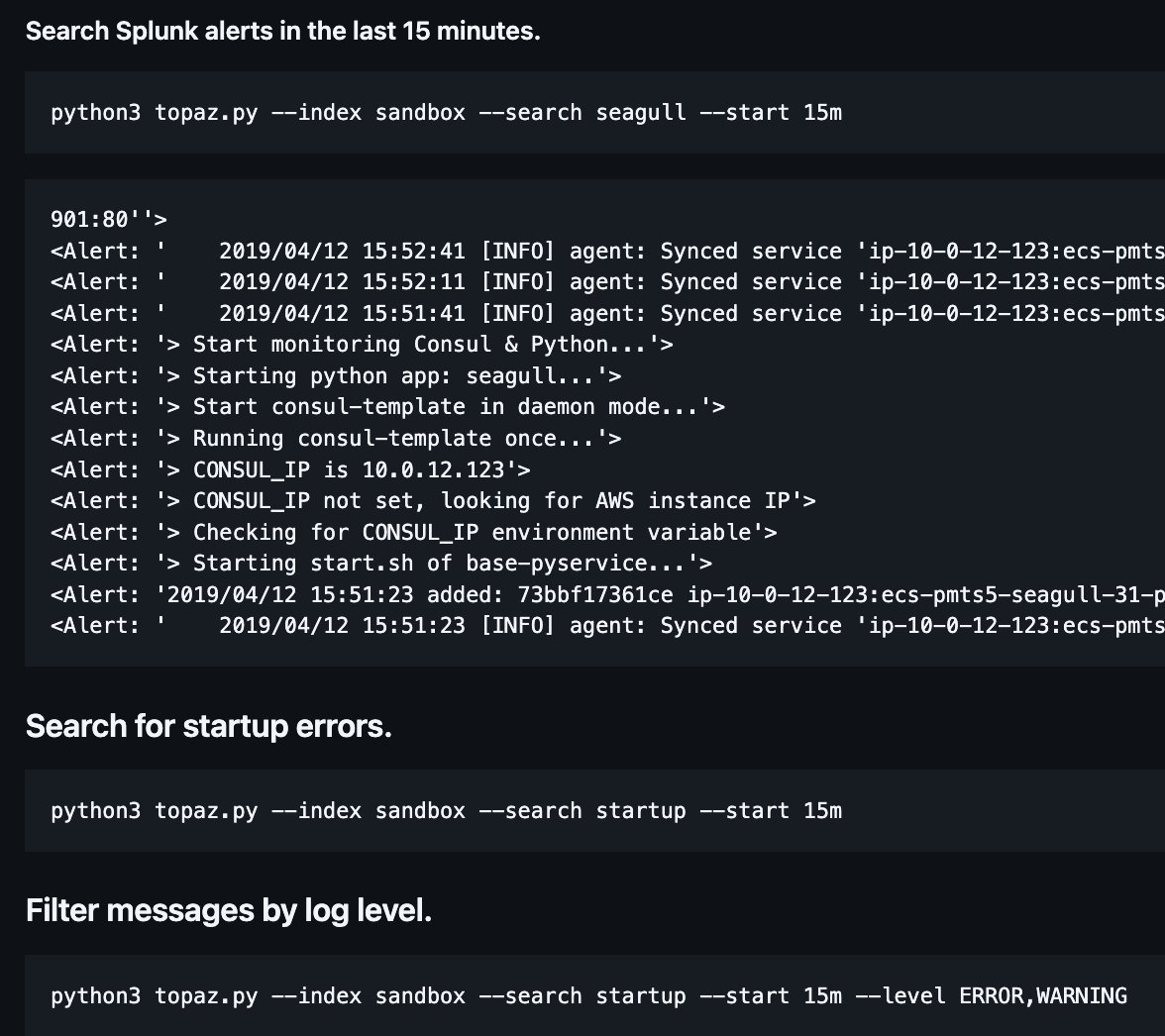
This project develops Python integration with Splunk for log analysis and monitoring, enabling efficient log processing and visualization. It offers a CLI and programmatic access to query logs, run searches, and automate operational insights from Splunk data.
PythonSplunk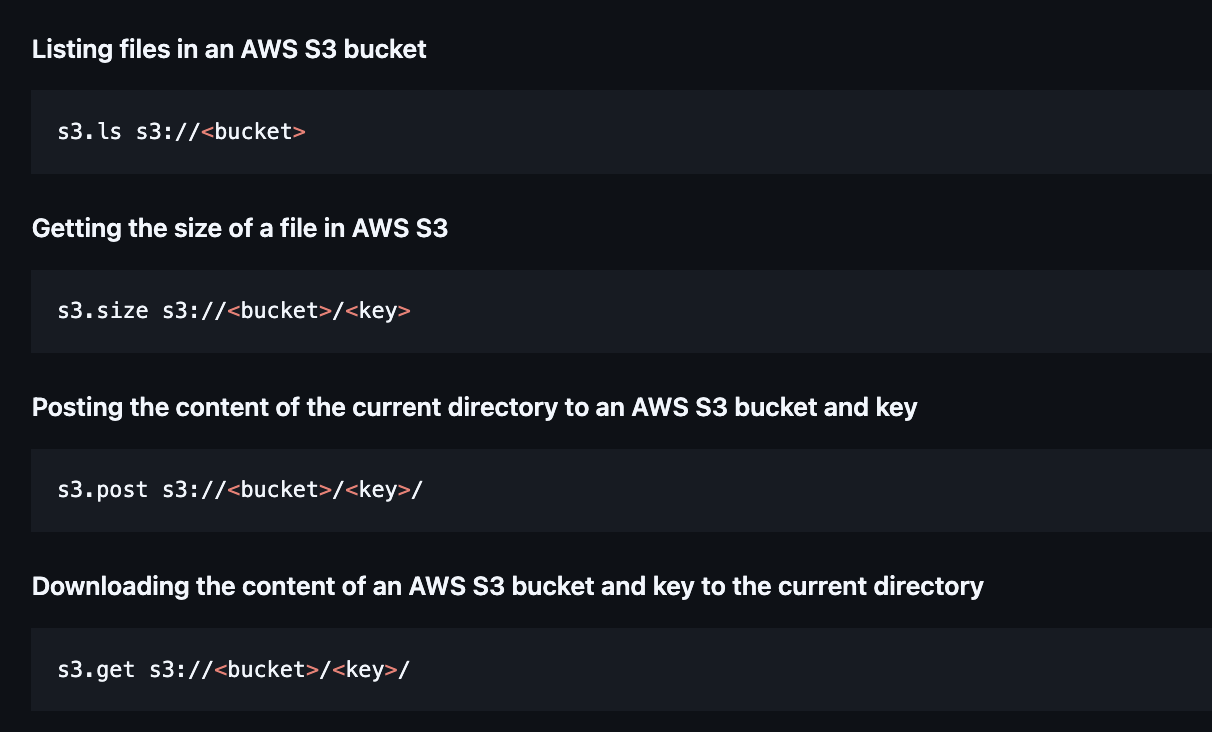
This project engineers file system management tools with AWS S3 integration, enabling efficient cloud storage operations and automation. It supports uploads, downloads, sync, and scripting for bulk and recurring storage tasks on Linux and cloud environments.
LinuxShell ScriptingAWS
This project creates comprehensive development tools for Python, Android, TypeScript, Django, Git, and GPT integration. It bundles scripts and utilities to streamline local development, version control, and AI-assisted workflows across multiple stacks.
Linux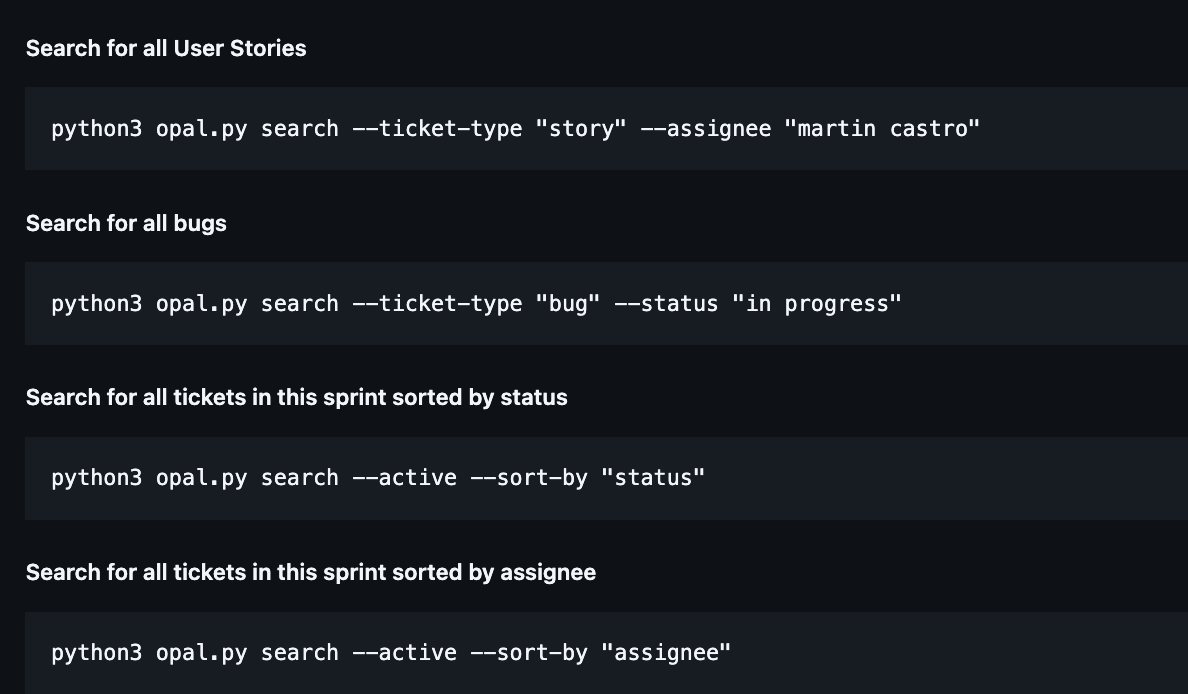
This project develops Python integration with JIRA, enabling automated issue tracking and project management. It provides a CLI and API helpers to create, update, and query issues and projects programmatically from scripts and toolchains.
JiraPython
This project engineers web scraping tools using Python and Beautiful Soup, enabling efficient content extraction and PDF conversion. It fetches web pages, parses structure and text, and generates PDFs for offline reading or archival.
PythonWeb Crawling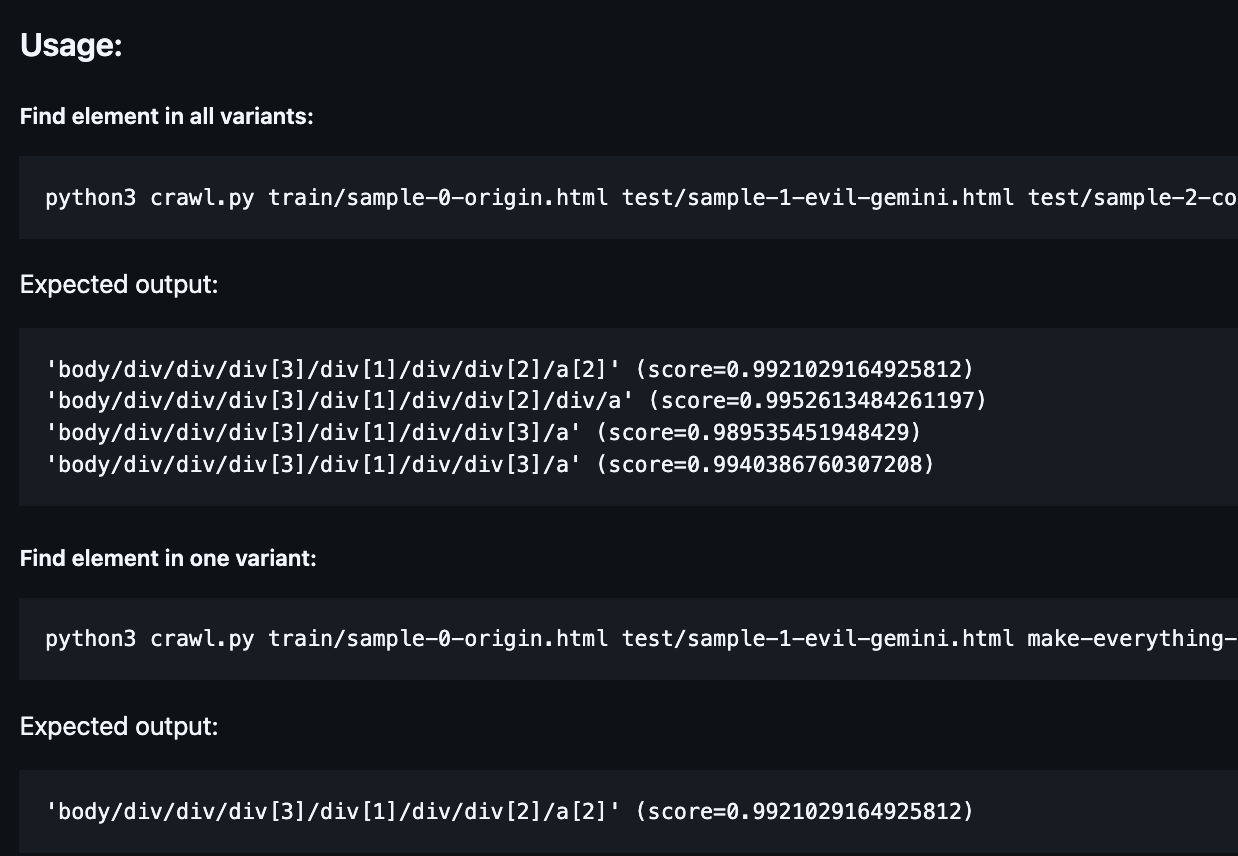
The project involved using Python and the asyncio library to create a web crawler that could efficiently scrape and process data from multiple websites simultaneously. The crawler was designed to handle large volumes of data by using asyncio's event loop to manage concurrent requests and minimize blocking I/O operations. The project also made use of other Python libraries such as requests, BeautifulSoup, and pandas to extract, process, and analyze the scraped data.
PythonBlockchain
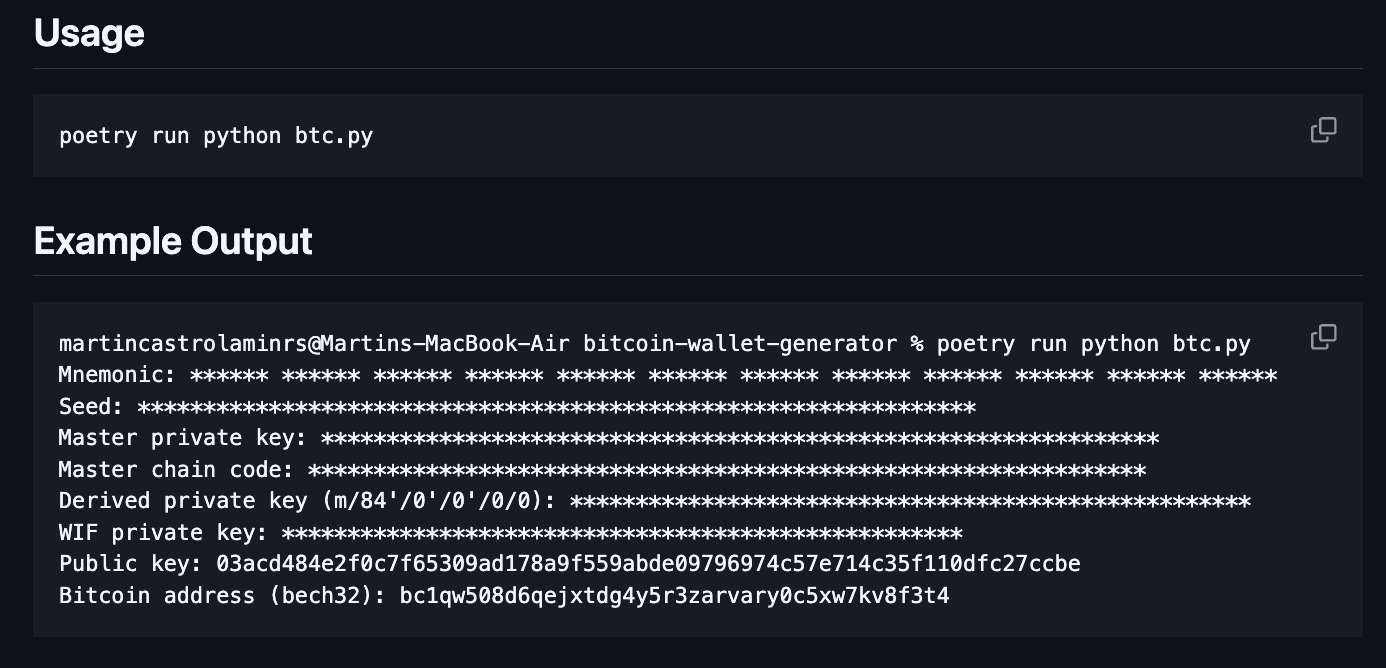
This project provides code for generating Bitcoin wallets that can store BTC without relying on third-party services like Blue Wallet or Electrum. It demonstrates key generation, address derivation, and secure storage of keys for self-custody of Bitcoin.
BTC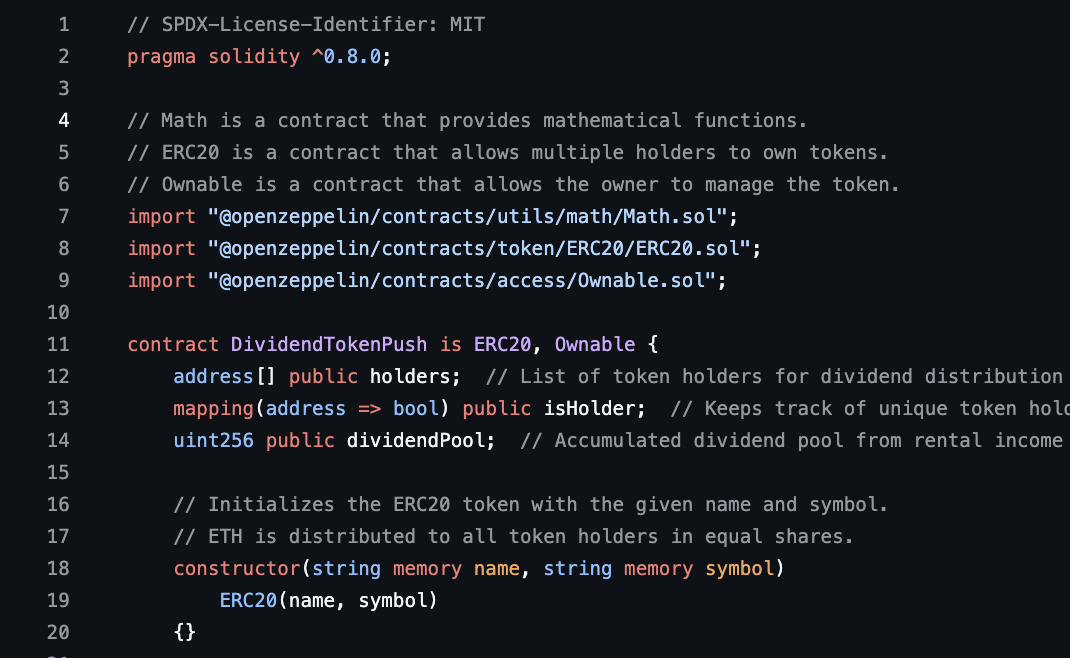
This project develops secure and auditable real estate smart contracts in Solidity, implementing Merkle trees for efficient property verification on-chain. It supports proof of ownership, transfers, and compliance checks in a decentralized real estate workflow.
SolidityEthereumEVMMerkle Tree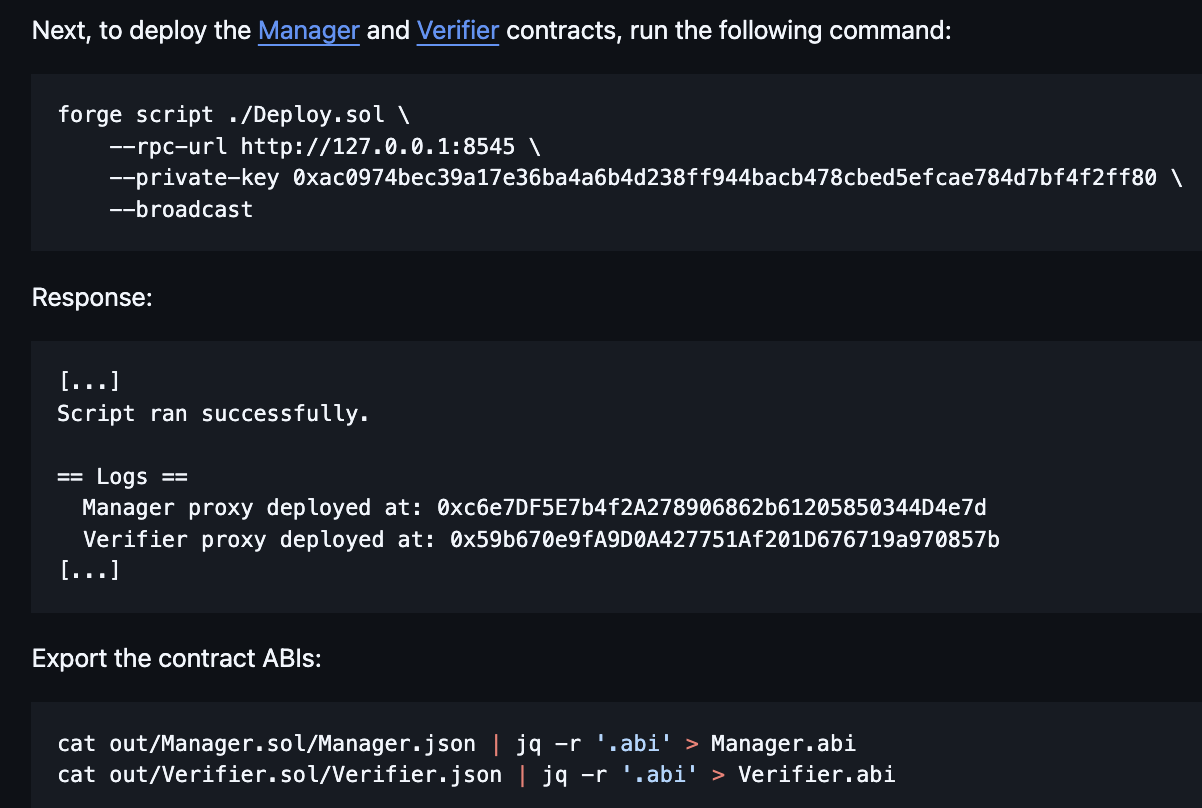
This project is a Solidity-based upgradeable smart contract system leveraging OpenZeppelin's upgradeable libraries to provide secure and flexible access control, signature verification, and contract management. It includes a Manager contract that handles role-based access control, pausability, upgradeability with state migration, and integration with an external Verifier contract for validating user signatures. Built with Foundry for testing and deployment, the system ensures security through strict role enforcement, robust error handling, and seamless upgrade mechanisms.
SolidityUpgradeableAccess ControlFoundryEthereumEVMOpenZeppelin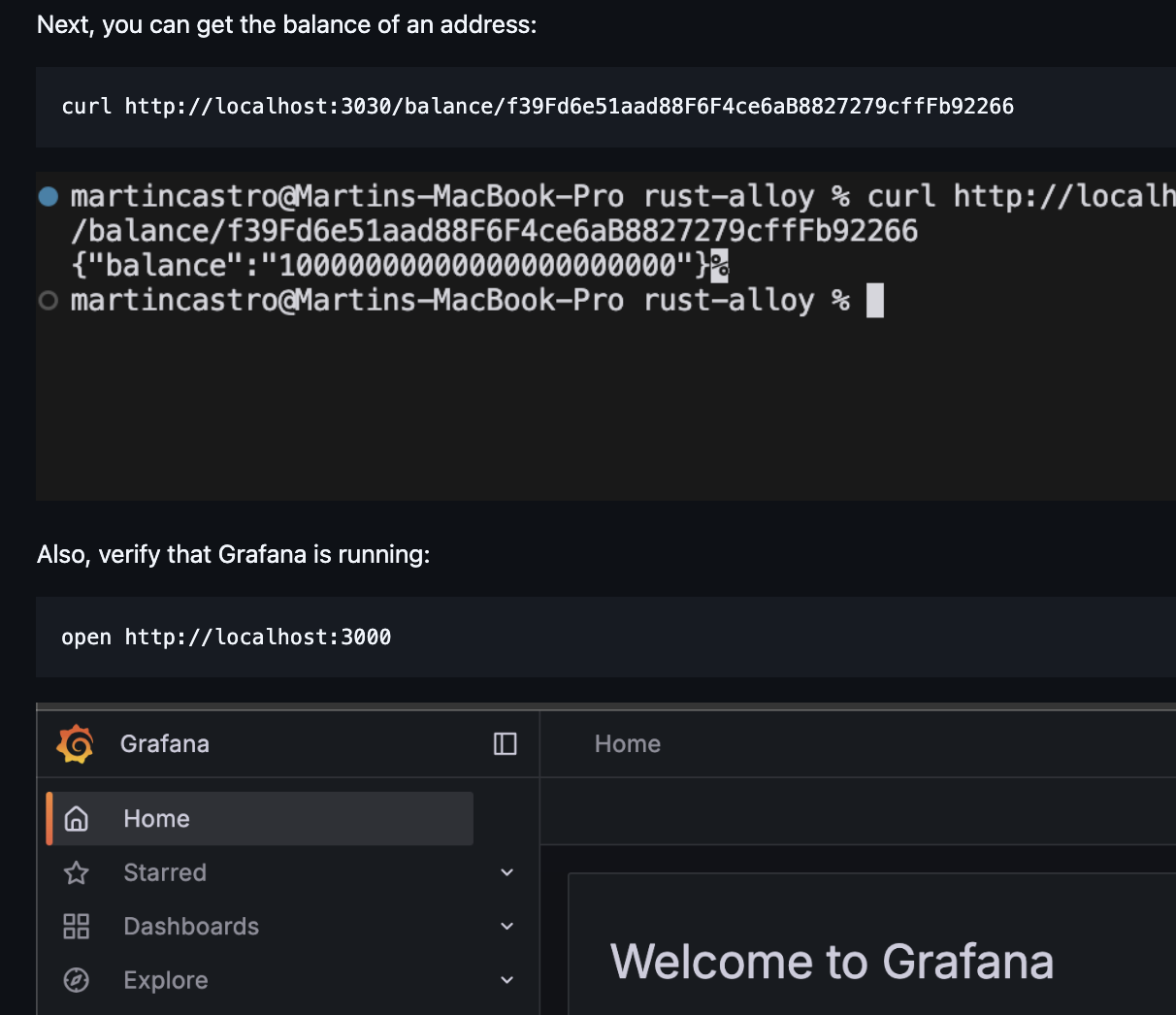
This project is a Dockerized Rust API that leverages Tokio, Warp, Alloy, Foundry, and Grafana to interact with Ethereum nodes, providing balance queries and real-time monitoring. It integrates Anvil for local Ethereum development, OpenTelemetry for tracing, and Prometheus + Grafana for monitoring, making it a robust solution for blockchain-based applications. The API is built with Warp for high-performance async HTTP handling and supports structured logging, CORS, and OpenTelemetry tracing. With a simple Docker Compose setup, it allows seamless deployment and local development, ensuring a production-ready Ethereum API environment.
RustTokioWarpAlloyFoundryGrafanaDocker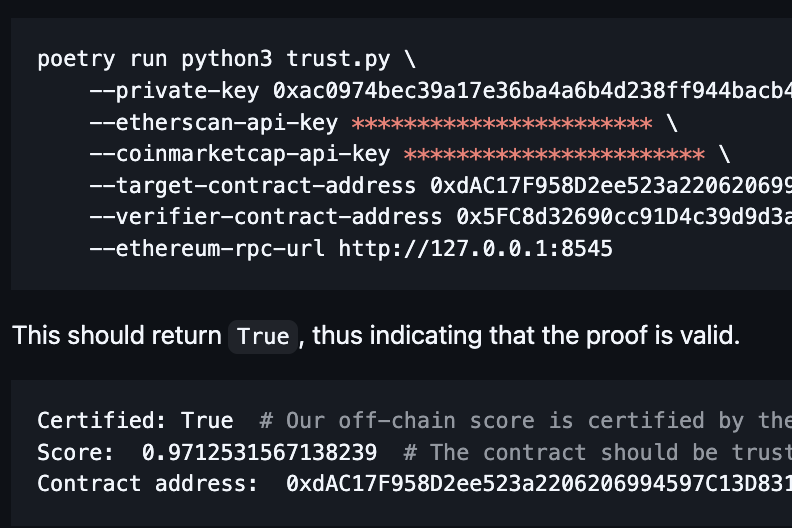
This project, titled zk-trust, leverages Zero-Knowledge Proofs to enhance security in the DeFi ecosystem by verifying the attributes of ERC20 tokens before they are listed on platforms. By implementing a robust validation mechanism off-chain and confirming the authenticity on-chain via a Solidity smart contract, this system helps prevent fraud similar to the recent Ionic Money Hack, ensuring only legitimate tokens are used within the platform.
Web3EthereumEtherscan APICoinMarketCap APIZero-KnowledgeZokratesDockerFoundrySolidity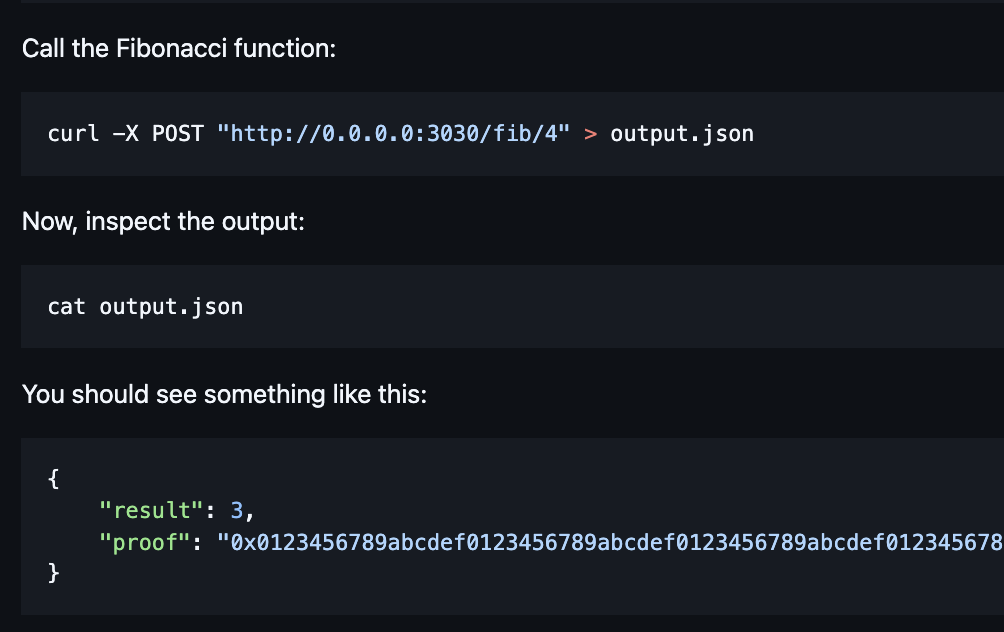
This project demonstrates a zero-knowledge proof system using RiscZero's zkVM. It compiles a guest program located in the ./methods/guest directory into an ELF binary, which is then executed by a host Rust application that also runs a Warp server. The server exposes endpoints to remotely trigger zkVM executions, allowing users to submit inputs, obtain the computed result along with a cryptographic proof of execution, and ultimately validate that proof on-chain. The entire process is containerized using Docker, ensuring a reproducible and isolated environment for development and deployment.
EthereumSolidityRustAlloyTokyoFoundryZKP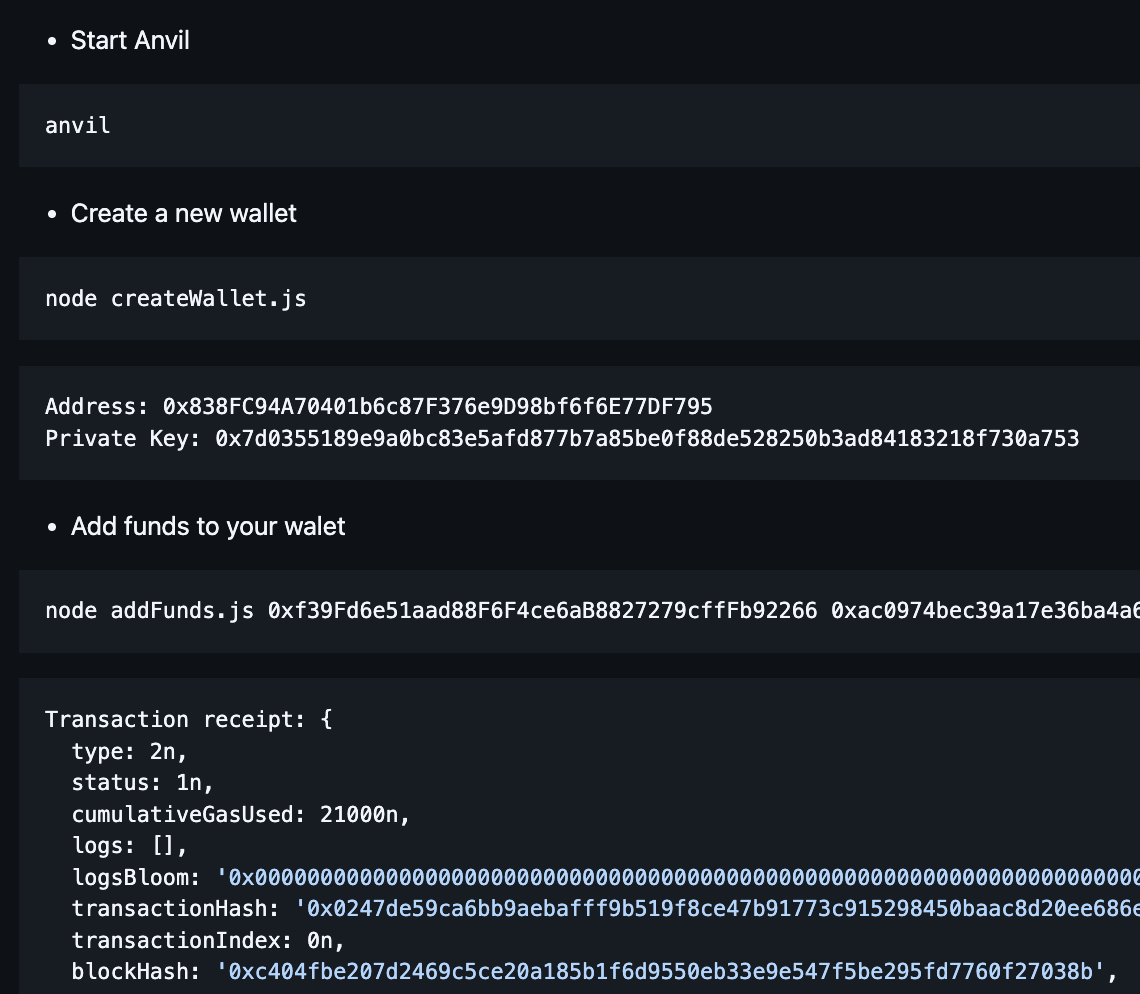
This project involved the development of an Ethereum-based application using the Web3.js library, which provided an engaging platform to interact with the blockchain. My role encompassed setting up a local development environment using Anvil, crafting scripts for sending transactions, and managing wallet balances. I successfully implemented functionality to handle cryptocurrency transactions dynamically by connecting to and interacting with a simulated Ethereum network. This experience enhanced my understanding of blockchain technology, Ethereum smart contracts, and the intricacies of transaction fee mechanisms.
EVMEthereumSolidityWeb3js
The project involved developing a smart contract on the Ethereum network using Solidity programming language. The contract was designed to facilitate a decentralized voting system that could be implemented across various organizations. The contract was created to ensure transparency and security in the voting process while also reducing the potential for fraud. Additionally, the project involved testing the smart contract using the Remix IDE and deploying it to the Ethereum network using tools like Ganache and Truffle. The smart contract was deployed on a private network and was also tested using the Ropsten test network.
EVMEthereumSolidity
The project involves building a cross-chain environment where users can log in to a Django SSO (Single Sign-On) server and access other Django servers connected to the Solana, Ethereum, and Polygon networks. The SSO server is responsible for authentication and authorization, while the other servers are responsible for interacting with their respective networks.
EthereumSoliditySolanaPolygon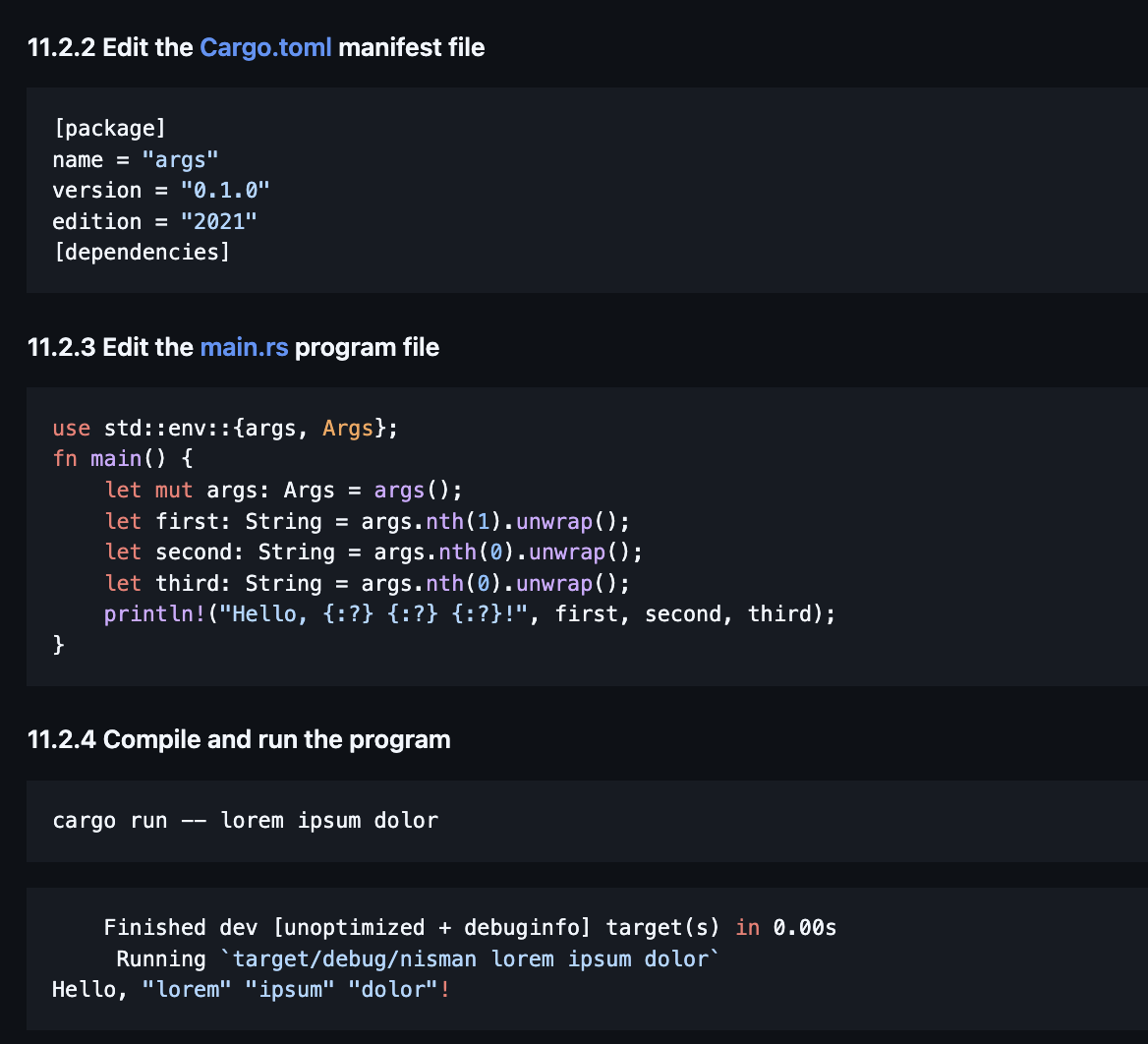
The project involved creating a Solana NFT using CandyMachine, a tool that allows creators to mint NFTs on the Solana blockchain, and Rust Programs. Rust was used to write the smart contract that governs the creation, distribution, and sale of the NFTs. The NFTs were stored on the Solana blockchain, making them easily transferable and secure.
SolanaRust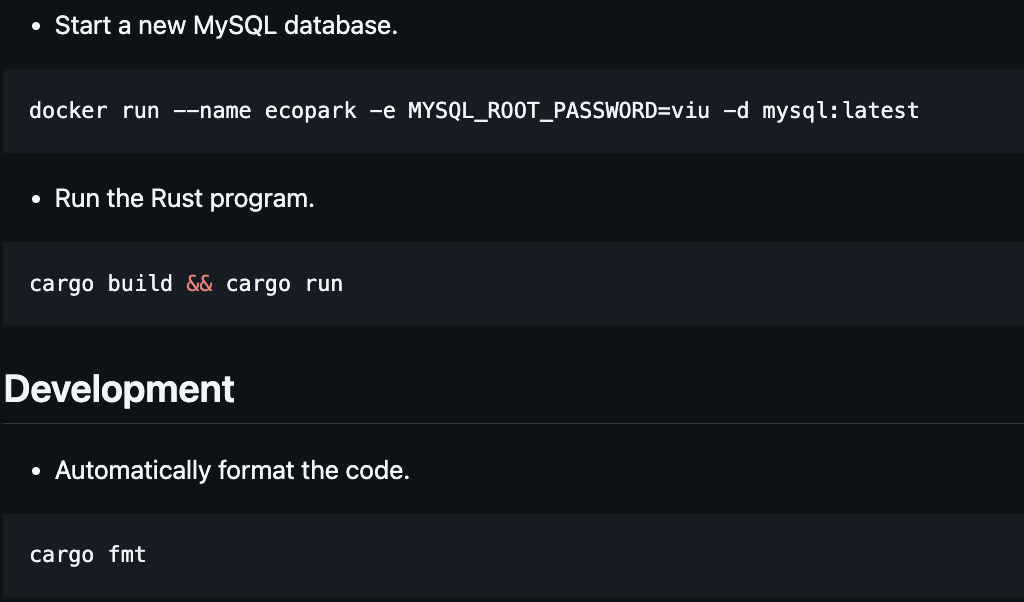
This project builds a high-performance database application in Rust, implementing efficient MySQL queries and Docker containerization. It offers a fast, reliable backend for data access and is designed for deployment in containerized and cloud environments.
RustMySQLDockerBackend
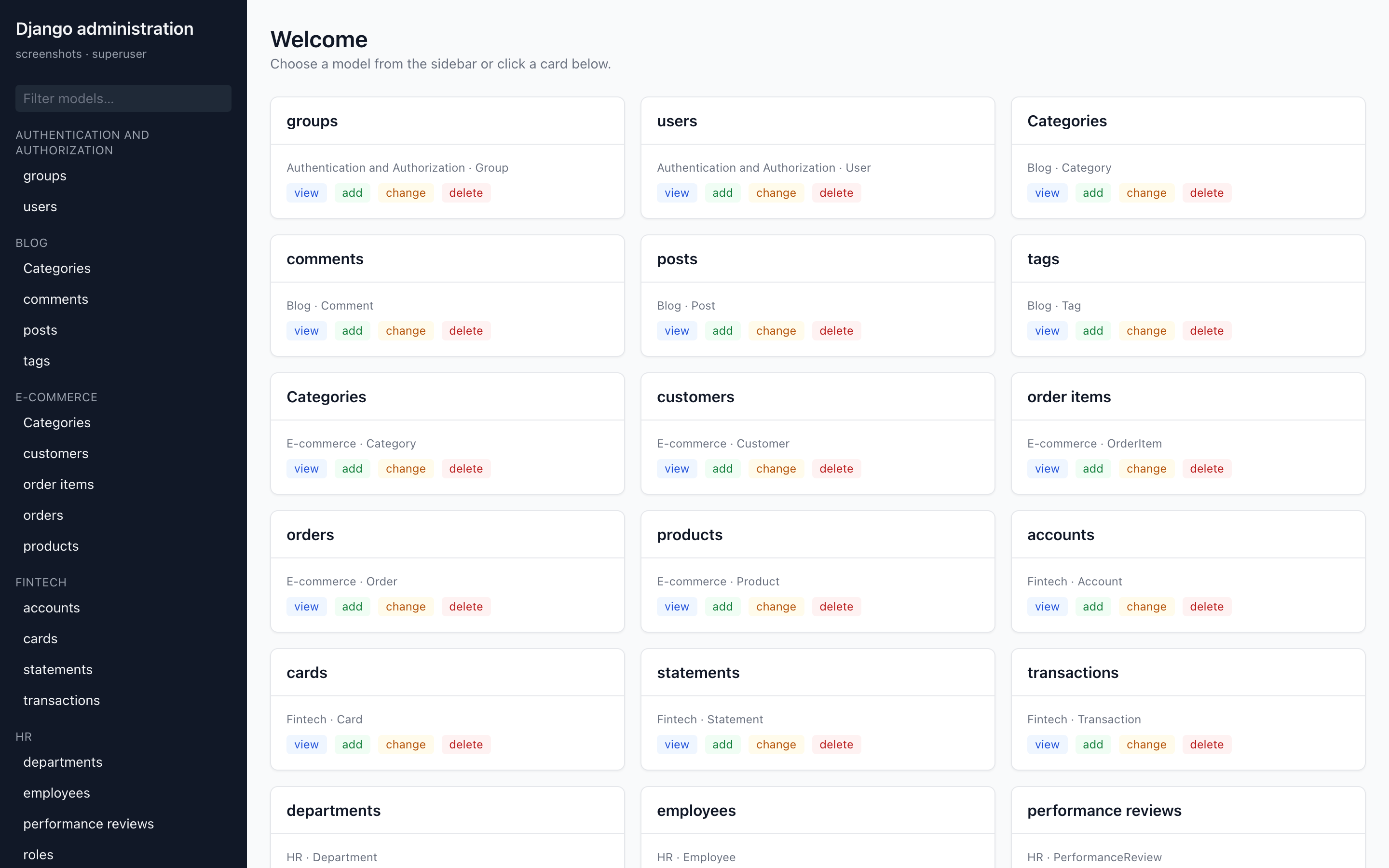
This project is a drop-in React single-page admin for any Django 5+ project, modernising Django's classic hypertext admin without requiring any frontend code from the developer. The package is metadata-driven: it learns your models, fields, and permissions at runtime from a registry endpoint, and renders virtualised tables, mobile-friendly layouts, inline editing, filters, search, bulk actions, autocomplete pickers, and inlines directly from your existing ModelAdmin classes. Permissions, querysets, fieldsets, and read-only rules are honoured verbatim, so a new ModelAdmin only requires a page refresh — no rebuild or codegen.
DjangoPythonReactTypeScriptREST API
This project exposes every ModelAdmin already registered on the Django admin site through a JSON REST API, without introducing a parallel permission system, a parallel form layer, or any feature the Django admin itself does not have. Authentication, authorization, field validation, actions, search, filters, and audit logging are all delegated to the existing Django setup: requests run through the same ModelForm, the same has_view/add/change/delete_permission checks, and Django's own LogEntry history. It is the stable wire surface that powers django-admin-react and django-admin-mcp-api.
DjangoPythonREST APIJSON
This project is an MCP (Model Context Protocol) adapter for the Django admin that lets AI agents read rows, retrieve, create, update, and delete records, run admin actions, and use autocomplete through the standard MCP protocol. It is a thin wire-protocol layer sitting on top of django-admin-rest-api — the same authentication, the same permissions, no extra validation, and no new business logic — so it safely exposes the Django admin's existing capabilities to LLMs.
DjangoPythonMCPLLMsAI Agents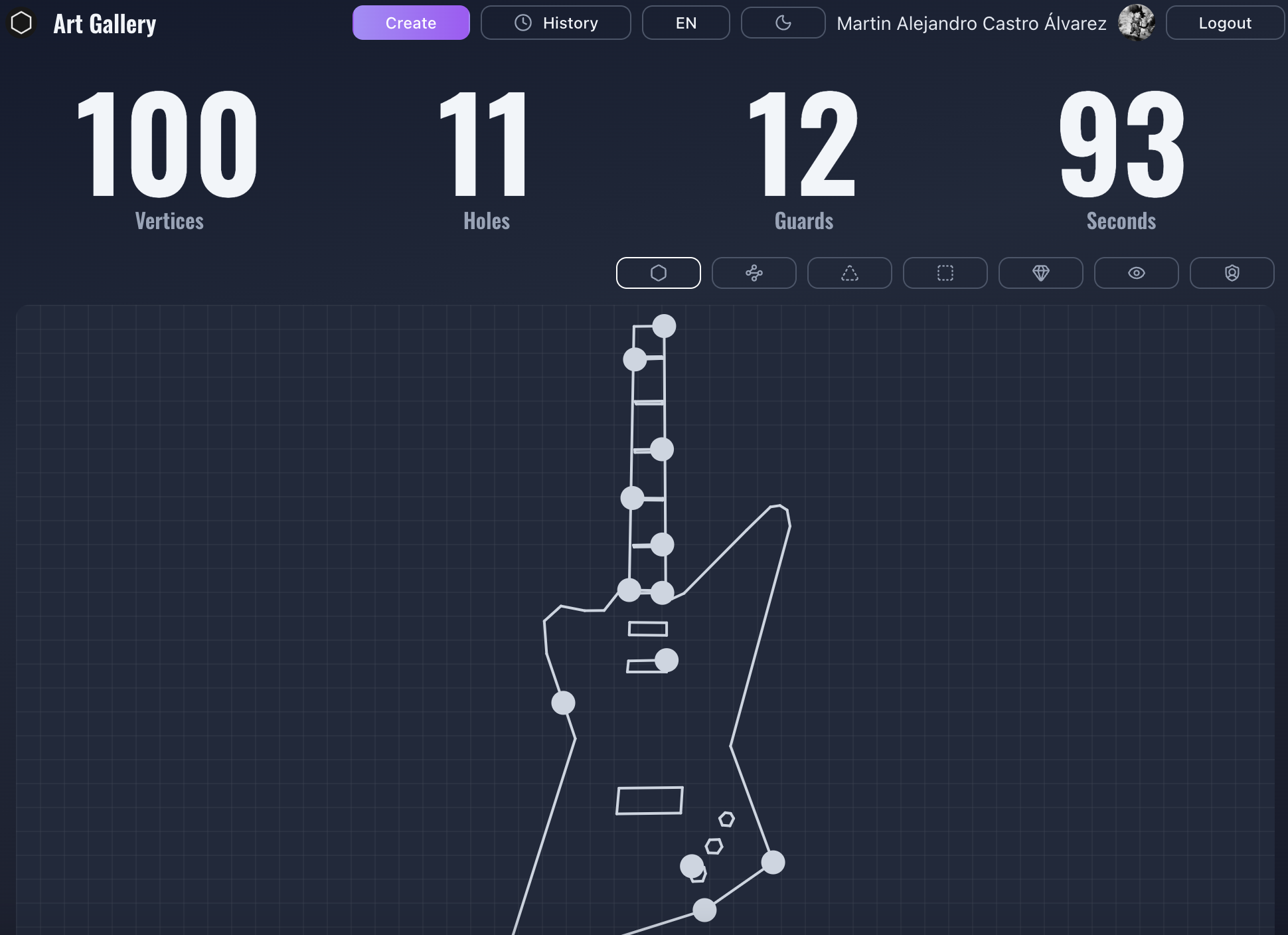
This project is a computational geometry application implementing art gallery algorithms, convex decomposition, and guard placement from first principles. It includes a React web app for visualization, a Python API for computations, and AWS CDK for deployment and hosting.
PythonTypeScriptReactAWS
This project engineers a high-performance REST API using FastAPI, implementing async operations and automatic OpenAPI documentation. It is designed for low-latency, scalable backends with built-in validation, dependency injection, and interactive API docs.
PythonFastAPI
The project is a geospatial application that leverages GeoDjango and PostGIS to create and manage multiple points, lines, and polygons. It calculates distances between these objects and performs various operations using them to support geospatial analysis and visualization.
DjangoPython
The project utilizes Hexagonal Architecture in Java Spring Boot for e-commerce management with a React and Tailwind frontend. It features domain models, service interfaces, and custom exceptions to streamline operations, supported by comprehensive unit tests. Key functionalities, including user and product management, are demonstrated in interactive demos. The architecture promotes modularity and ease of maintenance, ensuring adaptability and scalability through well-defined web and database API adapters.
JavaSpringBootHexagonal Architecture
The project involved utilizing NodeJS and TypeScript to dynamically render PDFs based on user input. NodeJS provided a reliable and efficient backend framework for handling data processing and file generation, while TypeScript was used to ensure type safety and code consistency. The project also made use of various PDF generation libraries such as pdfkit and Puppeteer to facilitate PDF rendering.
Node.jsJavaScriptTypeScript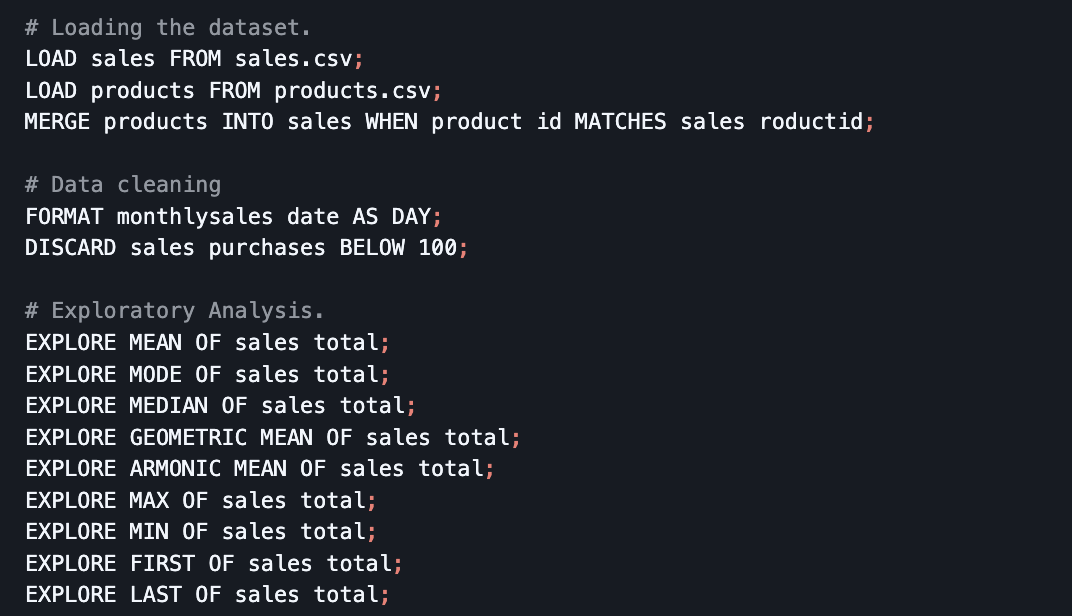
This project develops a custom programming language compiler for data scientists, implementing lexical analysis and parsing using Bison and Lex. It defines a small DSL and toolchain for expressing data and analytics operations with a dedicated syntax and runtime.
PythonBisonLex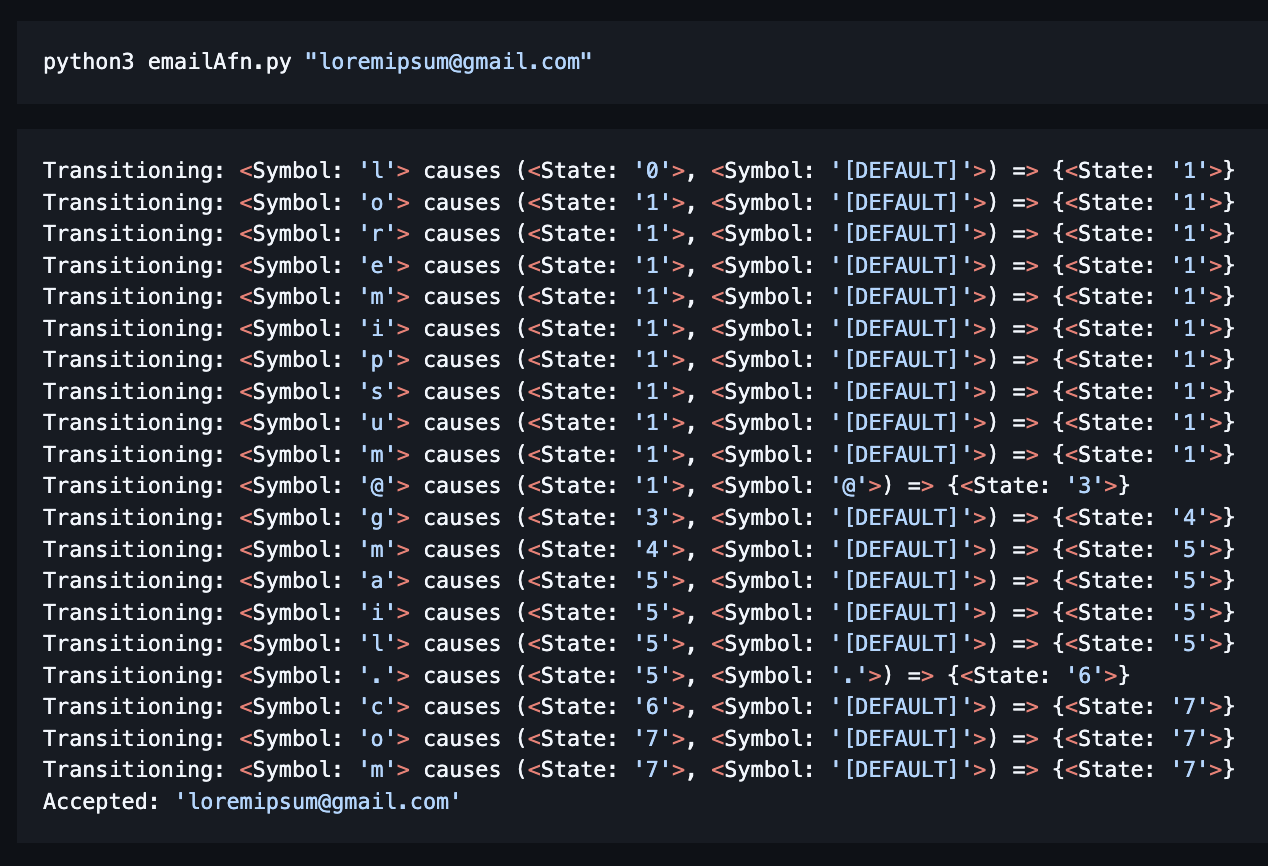
This project implements various automata algorithms in Python, enabling efficient pattern matching and language processing. It covers finite automata, regular expressions, and related constructs used in compilers, parsers, and text processing.
Python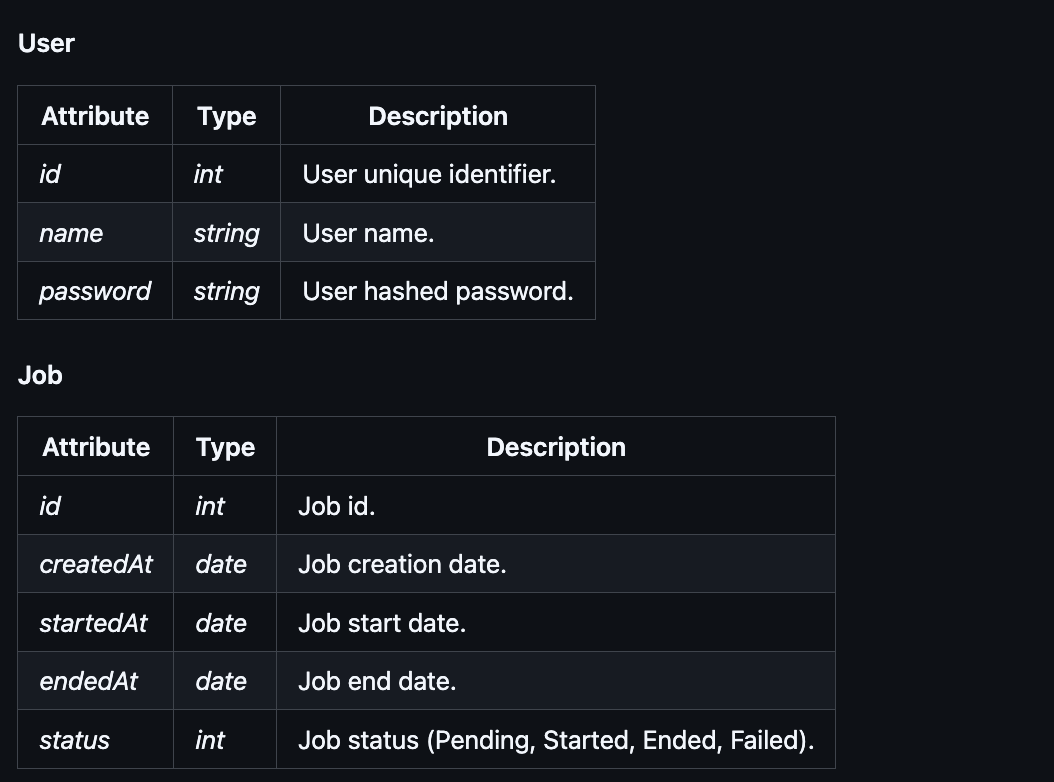
The project utilized Java Springboot as the main technology stack for building a web application. Springboot provided a framework for creating RESTful APIs, which were used to handle user requests and data retrieval from a MySQL database. The application also implemented security features such as user authentication and authorization using Spring Security. Overall, Springboot proved to be a reliable and efficient tool for building a scalable web application.
JavaSpringBoot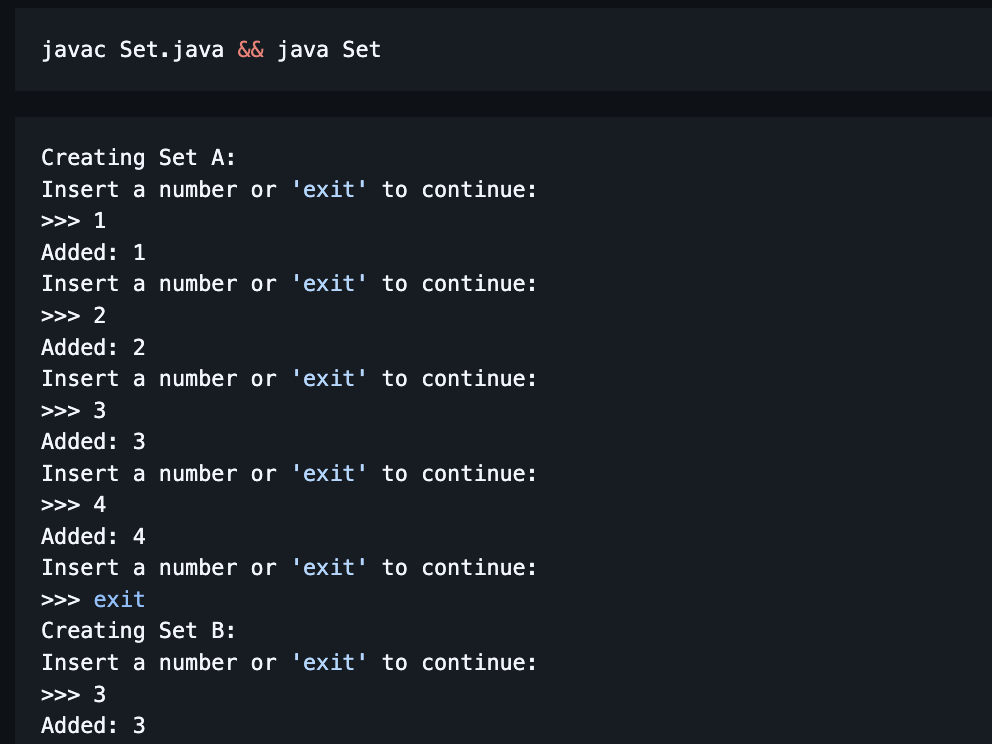
This project implements efficient data structures in Java, focusing on performance optimization and algorithm complexity. It provides well-tested implementations of trees, heaps, graphs, and other structures with clear APIs and complexity guarantees.
Java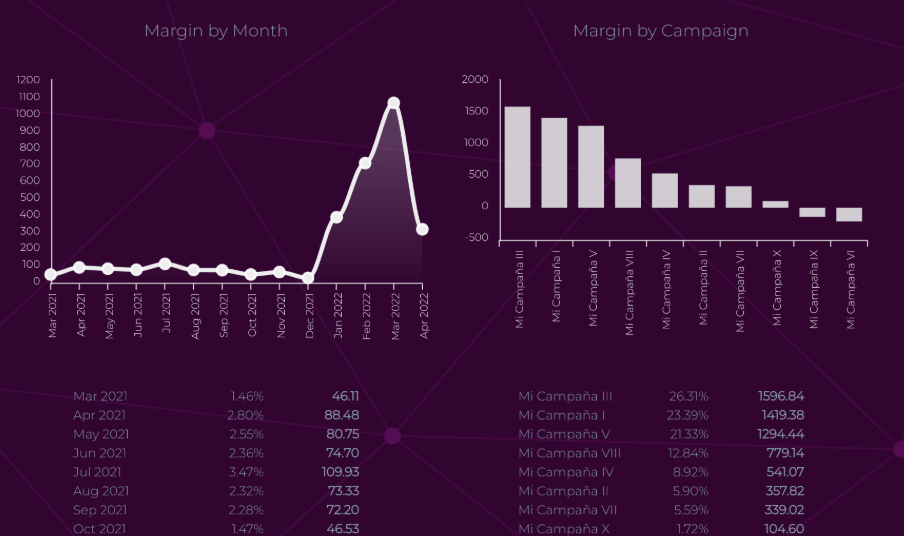
This project builds a comprehensive data analytics platform using Django, implementing PnL, LTV, and retention analysis. It offers dashboards, reports, and APIs for business and product metrics with a Django-backed storage and computation layer.
PythonDjango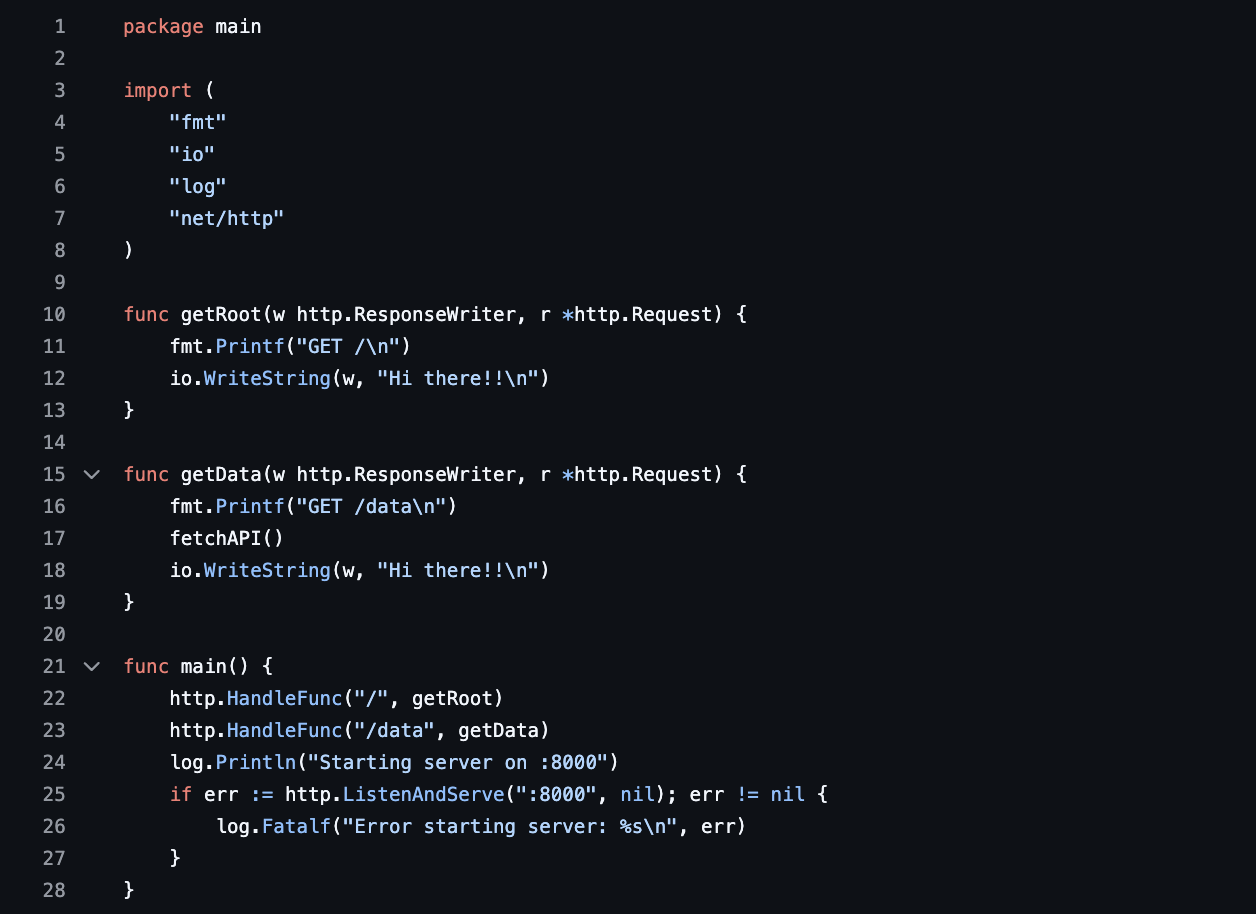
This project develops high-performance applications using Go, implementing concurrent processing and efficient resource utilization. It leverages goroutines and channels for concurrency and is suited for services requiring low latency and high throughput.
Go
This project is a Content Management System (CMS) built using the Django web framework. The CMS will enable users to create, edit, and publish digital content, such as articles, blog posts, and multimedia files, using an intuitive web-based interface. The CMS will also include features such as user authentication, content versioning, and search functionality.
DjangoPython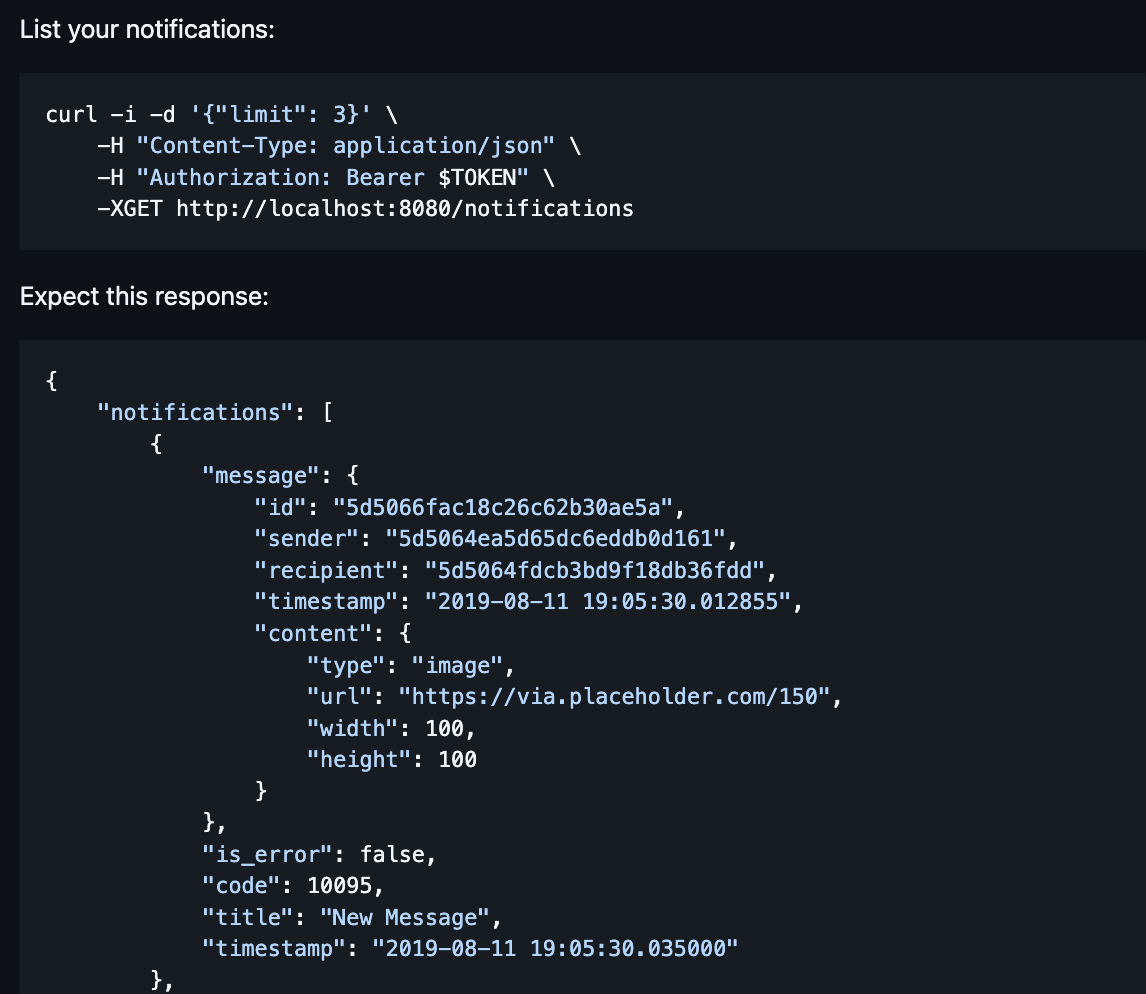
This project involved the implementation of a chat server using Redis, Celery, MongoDB, and Flask. Redis was used for message queueing and socket management, while Celery was used for asynchronous task processing. MongoDB was used to store user information and chat history, and Flask was used to provide the web interface. The project also involved implementing a RESTful API for mobile client communication.
PythonFlaskMongoDBRedisCelery
This project develops a file server using Flask and PIL, implementing efficient image processing and S3 storage integration. It serves and transforms images on demand and persists assets to AWS S3 for scalable media hosting.
PythonFlask
This project engineers a real-time chat server using Python sockets, enabling efficient network communication and message handling. It supports multiple concurrent clients and demonstrates low-level TCP socket programming and protocol design.
PythonSockets
This project develops Python integration with Google Spreadsheets, enabling automated data processing and analysis. It uses the Google Sheets API to read, write, and transform spreadsheet data from scripts and pipelines.
PythonGCP
This project implements various software design patterns in Python, demonstrating best practices for maintainable and scalable code. It includes examples of creational, structural, and behavioral patterns with clear use cases and trade-offs.
PythonFrontend
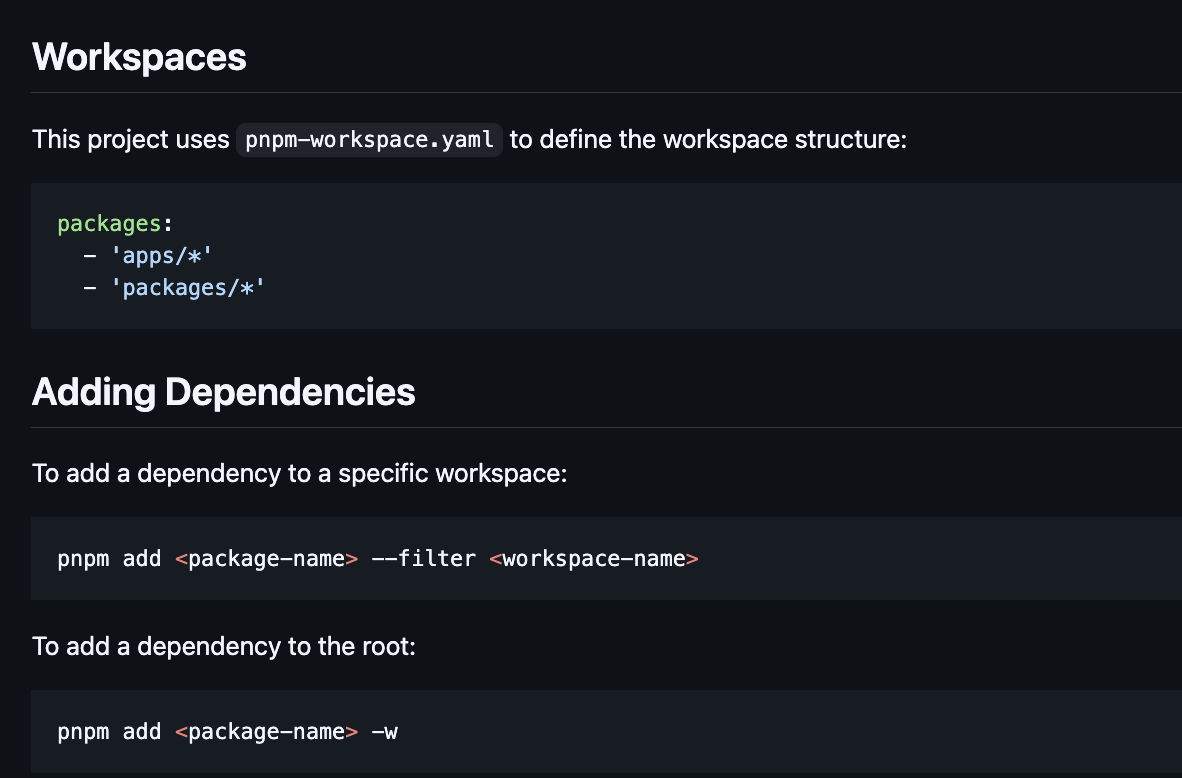
This project is a monorepo template for sharing UI components between React web and React Native mobile apps using pnpm workspaces. It demonstrates platform-specific implementations with Vite, Expo, and TypeScript in a scalable architecture for cross-platform development.
ReactReact NativeNode.jsJavaScriptpnpmViteExpoTypeScriptMonorepo
The project is centered on implementing a distributed frontend architecture for medium and large companies. It aims to enhance scalability and maintainability in web development by modularizing the frontend, thus facilitating smoother collaboration and more agile processes in complex, large-scale applications.
ReactNode.jsJavaScriptMicrofrontendsMicroservices
This project builds a modern web application using Next.js, implementing server-side rendering and optimized performance. It leverages file-based routing, API routes, and static or dynamic rendering for fast, SEO-friendly web experiences.
Node.jsJavaScriptReactNext.js
This project develops a responsive web application using Vue.js and TypeScript, implementing component-based architecture. It uses the Composition API and type-safe patterns for maintainable, reactive user interfaces and single-page applications.
Node.jsJavaScriptVue.jsTypeScript
This project engineers a high-performance web application using Svelte, implementing reactive programming and efficient DOM updates. It compiles to minimal JavaScript and uses reactive declarations for fast, lean front-end experiences without a virtual DOM.
Node.jsJavaScriptSvelte
This project builds a type-safe React application using TypeScript, implementing modern frontend development practices. It combines React components with strict typing, hooks, and tooling for reliable and maintainable user interfaces.
Node.jsJavaScriptReactTypeScript
The project is a React application that uses Firebase and Google OAuth 2.0 authentication for secure user access to protected resources. It includes custom login and registration forms, and utilizes modern web technologies such as React, JavaScript, and CSS. Integration with third-party libraries and services enhances the overall reliability and robustness of the application.
Node.jsJavaScriptReactFirebase
The project is a web development endeavor aimed at implementing flexbox, a powerful layout system used in modern CSS, with a focus on creating flexible and responsive designs. Through this project, developers will gain an understanding of the different properties and techniques that can be utilized to achieve custom layouts for their web pages. By leveraging flexbox, users will be able to create dynamic and adaptive interfaces that adjust to the size and orientation of various devices.
Node.jsJavaScriptCSS3
This project engineers efficient data processing using TypeScript, implementing map-reduce patterns for large datasets. It demonstrates how to partition work, aggregate results, and handle streaming or batch data in a type-safe Node or browser environment.
TypeScriptNode.jsJavaScript
This project builds a full-stack MVC application using TypeScript, MongoDB, and NestJS, implementing clean architecture principles. It provides a structured backend with dependency injection, modules, and MongoDB integration for scalable API and data layers.
Node.jsJavaScriptTypeScriptMongoDBNestJS
This project implements object-oriented programming patterns in TypeScript, demonstrating advanced class design and inheritance. It covers encapsulation, abstraction, and type-safe OOP constructs for structuring front-end or Node.js applications.
Node.jsJavaScriptTypeScript
Full-stack digital asset management with a React 19 and TypeScript frontend (Vite, Tailwind CSS, React Router, Formik, Yup) and a Firebase backend: Auth, Firestore, Cloud Storage, and Node.js Cloud Functions. Local development runs the Firebase Emulator Suite in Docker for isolated Auth, Firestore, Storage, and Functions.
ReactTypeScriptViteTailwindFirebaseFirestoreCloud FunctionsDockerTesting
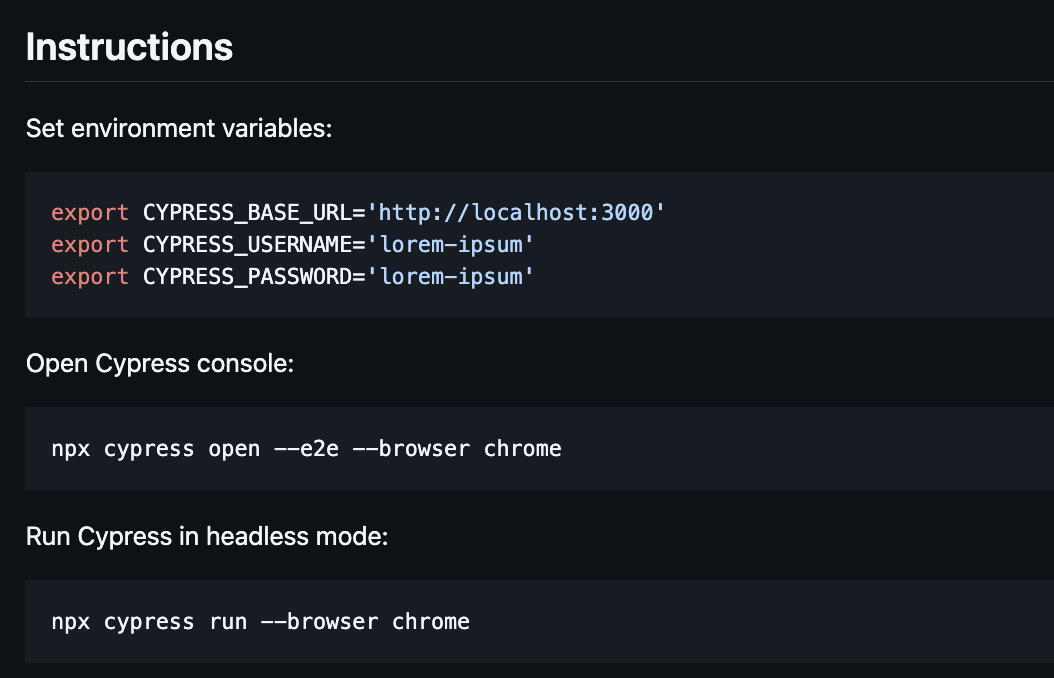
This project showcases the integration of Cypress tests within a web development environment, emphasizing the crucial role of automated testing in building robust, error-free applications. By leveraging Cypress, an advanced end-to-end testing framework, the project aims to demonstrate best practices in test automation for both small and large-scale web projects.
Node.jsJavaScriptReactCypress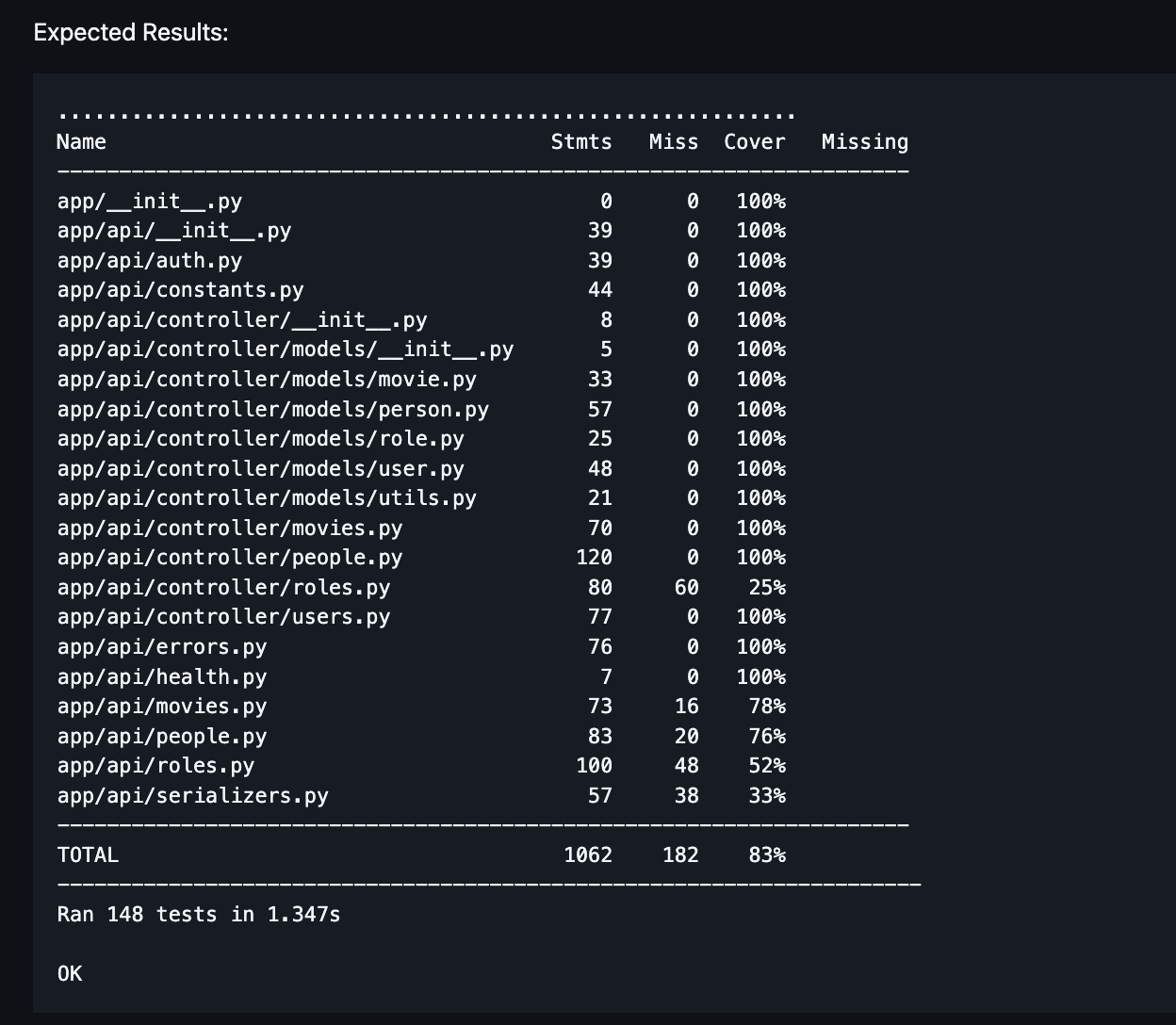
This project engineers a Flask REST API with 100% unit test coverage, implementing robust testing practices and continuous integration. It serves as a reference for building well-tested Python APIs and integrating them into CI/CD pipelines.
FlaskPythonUnit Tests
This project builds an automated testing framework using Selenium WebDriver, enabling comprehensive browser-based testing. It automates user flows, assertions, and cross-browser checks for reliable end-to-end and regression testing of web applications.
SeleniumMobile
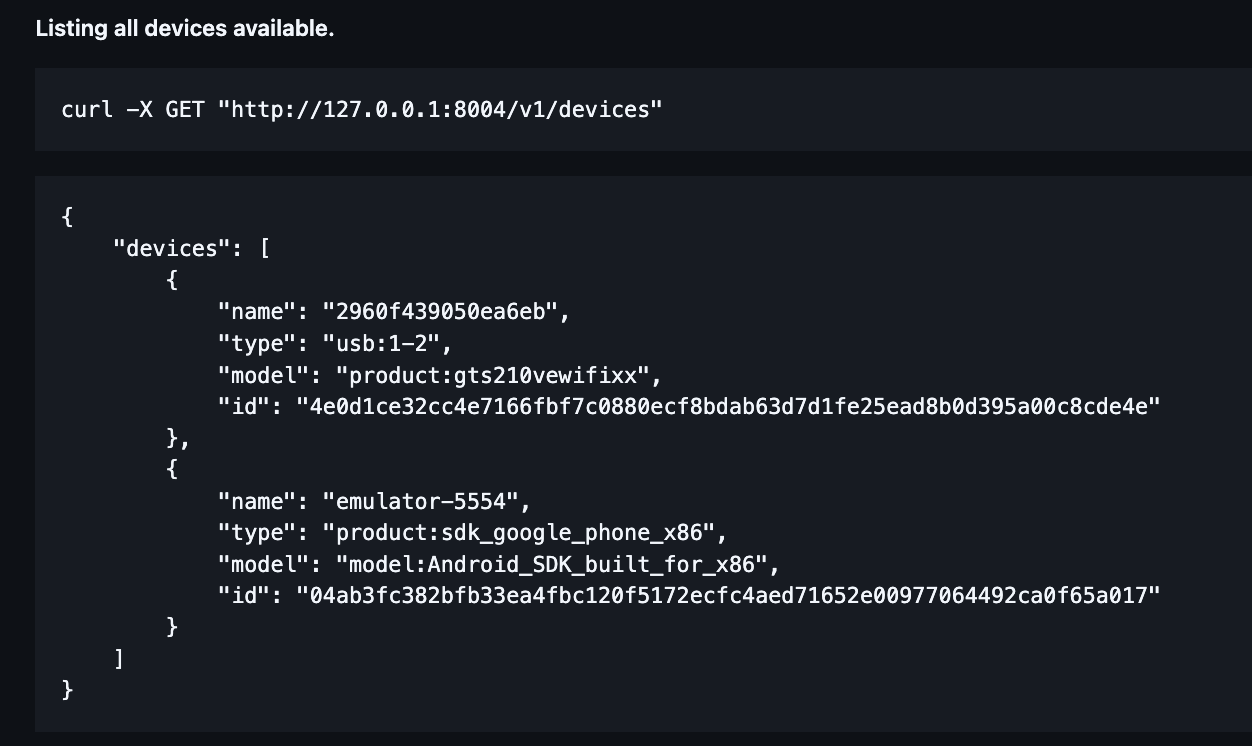
This project develops a web API for remote Android device emulator management, enabling efficient mobile testing and automation. It allows teams to control emulators, install builds, and run tests from CI or scripts for scalable mobile QA workflows.
AndroidLinux
This project engineers a native Android calendar application, implementing efficient data management and user interface. It provides event creation, editing, and scheduling with a native UI and local or synced storage for personal or educational use.
AndroidQuantum Computing
The project involved using Java to implement quantum algorithms for various applications. Java was chosen for its versatility, and the quantum algorithms were implemented using the Qiskit library. The project also utilized various quantum simulators to test the algorithms, including the IBM Quantum Experience platform. Overall, the use of Java proved to be effective in implementing complex quantum algorithms, and the project provided valuable insights into the potential applications of quantum computing.
Quantum ComputingJava
This project develops digital logic circuits using Logisim, implementing assembly language programming and circuit simulation. It demonstrates how to design and simulate low-level hardware and instruction sets for educational or prototyping purposes.
LogisimAssemblyAI Agents
langchain-virtual-assistant: This project delivers an AI-powered virtual assistant built with LangChain and RAG, enabling context-aware conversations and document analysis powered by OpenAI's GPT models. It allows users to query documents and hold coherent, context-rich dialogues with intelligent retrieval and generation capabilities.
llm-react-api: This project is a React-based single page application, styled using TailwindCSS, that allows users to explore and analyze character interactions in Project Gutenberg e-books. The application leverages a Language Learning Model (LLM) to process the text of e-books and visually represent character interactions through an interactive network graph. The application is deployed on AWS using the AWS Cloud Development Kit (CDK), which automates the setup of AWS Lambda for backend processing and API Gateway for handling requests efficiently.
sql-cursor-ai-agent: This project is a tool that helps you create SQL queries using AI technology. It has a web interface that works like Cursor, making it easy to use. The system uses two different AI agents that work together: one agent talks with you to understand what you need, and another agent creates the actual SQL code.
langchain-agent-streamlit: This project represents a cutting-edge integration of LangChain and Large Language Models (LLMs) to enhance the processing and comprehension of web search results, aiming to refine and reconstruct truncated information for improved clarity and user engagement. By leveraging advanced NLP techniques and custom tool development, we have successfully created an intelligent agent capable of consulting previous messages, conducting web searches, and presenting human-readable summaries without the common ellipsis truncation.
gpt-context-injection: This project focuses on leveraging the powerful combination of the GPT API, Elasticsearch, and SpaCy to implement a specialized chatbot capable of context injection. The chatbot's primary objective is to ingest and analyze data from a specific WordPress blog, providing relevant and contextual responses to user queries.
openclaw-agent: This project is an autonomous AI agent client that uses the OpenClaw SDK to connect to a local OpenClaw gateway over WebSocket for agent interactions, including messaging channels such as WhatsApp and Telegram. It includes a Docker-based gateway and integration with Google Vertex (Gemini) for scalable, cloud-backed agent workflows.
Deep Learning
higgs-boson-machine-learning: This project develops advanced machine learning models to detect Higgs boson signals in particle physics data, utilizing scikit-learn for feature engineering and statistical analysis. It includes comprehensive data visualization with Matplotlib and Seaborn to explore and validate model performance on high-energy physics datasets.
html2vec: The project involved developing an algorithm to convert HTML documents into vectorized objects suitable for use with neural networks. The algorithm used a combination of techniques, including HTML parsing, natural language processing, and dimensionality reduction. The resulting vectors could then be used as inputs for machine learning models to perform tasks such as document classification or information retrieval. The implementation was done in Python, using libraries such as BeautifulSoup and Scikit-learn.
search-keras-gensim-elasticsearch: This project builds a semantic search engine that combines Word Embeddings (GloVe) with Elasticsearch, enabling efficient text similarity search and content recommendation. It leverages Keras and Gensim for embedding generation and integrates with Elasticsearch for scalable indexing and retrieval of document collections.
deep-age-classifier: This project develops a CNN-based age detection system using Keras, implementing transfer learning for accurate facial age estimation from images. It includes comprehensive data preprocessing pipelines and is designed for robust performance on real-world face datasets.
keras-nltk-topic-modeling: Implementation of a Neural Network to classify text with Python and Keras. Python Keras NLP Neural Networks Text Classification Topic Modeling Matplotlib SpaCy POS tagging Lemmatization.
keras-document-classifier: The project involved building a document classifier using a neural network implemented with Keras. Data was scraped using the Newspaper3k library and the Google Search API to obtain a corpus of articles related to the topic. The articles were preprocessed using spaCy for POS tagging and lemmatization. The model was trained on this data and evaluated using various performance metrics. AsyncIO and aiohttp were used for asynchronous data retrieval and web scraping, respectively.
python-recommender-systems: This project creates a fully serverless personalized recommendation engine using AWS Lambda, NumPy, and Algolia, delivering low-latency suggestions through collaborative filtering and novelty and diversity algorithms. It is designed for scalable, cost-effective recommendation APIs without dedicated servers.
graph-link-prediction: The project utilizes Keras and Deep Learning to perform link prediction in a heterogenous information network, enabling accurate predictions between entities of different types.
python-deep-learning-algorithms: This project implements advanced deep learning algorithms in Python, focusing on efficient numerical computing with NumPy and scientific computing with SciPy. It demonstrates core concepts and optimizations used in building and training neural networks and related models.
supply-chain-optimization: This project engineers a supply chain optimization system using Python and NumPy, implementing efficient algorithms for logistics and resource allocation. It addresses routing, inventory, and allocation problems with numerical and optimization techniques suitable for real-world constraints.
python-monte-carlo-simulator: This project builds a sophisticated Monte Carlo simulation framework using Python and SciPy, enabling complex probabilistic modeling and statistical analysis. It supports scenario generation, sampling, and result aggregation for applications in finance, science, and engineering.
statistical-distributions: This project aims to utilize the powerful scipy library to perform statistical analysis on various distributions and identify the ones that best fit a given dataset. The project will involve analyzing and visualizing the results to gain insights into the underlying distribution of the data.
genetic-paper: This project implements genetic algorithms with a focus on algorithmic complexity analysis, enabling efficient optimization and problem-solving strategies. It uses mutation, crossover, and selection to evolve solutions and includes analysis of performance and scalability.
Computer Vision
opengl-samples: This project demonstrates advanced OpenGL rendering techniques by implementing a real-time 3D scene with multiple camera perspectives. It features three distinct geometric objects (a cube, a pyramid, and a prism) rendered with Phong-Blinn lighting and dynamic shading. The application showcases both a primary and a secondary camera, with the secondary camera's view displayed as a floating minimap overlay within the main window. The project includes custom framebuffer management, real-time object animation, and interactive window resizing, all built using modern OpenGL (Core Profile 3.3), GLFW, GLEW, and GLM for matrix and vector operations.
image-classification-transformer: This project involves developing a deep learning model for classifying different types of apparel from images, such as T-shirts, trousers, pullovers, dresses, and more. Using a pre-trained Vision Transformer (ViT) as the base model, the project enhances it with additional layers to improve classification accuracy. The model is trained with techniques like data augmentation, batch normalization, and dropout to reduce overfitting and enhance performance. The training process includes handling class imbalances by sampling more instances of underrepresented classes, and the optimizer is fine-tuned to focus on these new layers.
keras-image-detection-classification: The project involved building a model for text classification by first conducting topic modeling using the Natural Language Toolkit (nltk) in Python. After identifying the most relevant topics, a neural network was implemented using the Keras library to classify text into those topics. The text was preprocessed using SpaCy for part-of-speech tagging and lemmatization. The accuracy of the model was visualized using Matplotlib. The project also included a comparative analysis of the performance of the neural network model against other classification models.
python-video-processing: The program uses MoviePy to manipulate video files, OpenCV2 to perform image processing, and NumPy to manipulate arrays of video data. The project involves complex algorithms for transforming video frames, including blending, resizing, and overlaying videos. The movie generator is highly customizable, allowing users to adjust settings such as the video duration, frame rate, and output format.
media-tools: This project builds a video processing pipeline using FFMPEG, implementing efficient media conversion and manipulation through shell scripting. It automates encoding, decoding, format conversion, and batch processing of video and audio files from the command line.
Data Engineering
pyspark-docker: This GitHub project demonstrates the innovative integration of PySpark within Docker containers, illustrating a scalable and efficient approach to processing large datasets in distributed computing environments. By leveraging Docker's virtualization capabilities alongside PySpark's powerful data processing engine, the project offers a blueprint for building and deploying scalable data analytics applications. It showcases how to encapsulate PySpark applications in Docker, ensuring consistency, portability, and ease of deployment across different environments.
apache-hive-docker: The project involved implementing a Hive server using Docker Compose, which reads and writes data to HDFS. The project also included using the Hive CLI, web interface, and Python PyHive library to interact with the Hive server. The goal was to demonstrate the versatility and ease of use of Hive and Docker Compose in setting up and managing a data processing pipeline with HDFS.
hadoop-hdfs-map-reduce-docker: The project involved setting up a Hadoop Distributed File System (HDFS) using Docker and Docker Compose, followed by submitting a MapReduce job to the cluster. The web interface of the History Server was used to monitor the progress of the job.
hadoop-hdfs-kafka-docker: This project leverages Docker Compose to run an Hadoop Distributed File System (HDFS) cluster, along with YARN and ZooKeeper, as well as Kafka. Python is used as both the producer and consumer to send and consume data into a Kafka topic, enabling distributed data processing and storage using a familiar language and ecosystem.
hadoop-hdfs-hbase-docker: The project is a Docker-based solution for storing unstructured data in HBase with HDFS as the underlying storage system. It includes a Python client for easy data storage and retrieval, making it an ideal solution for managing large volumes of data.
sparkql: This project develops efficient SparkSQL queries for big data processing, enabling complex data transformations and analytics. It demonstrates how to structure and optimize SQL-style operations on distributed datasets using Apache Spark.
pandas-geo-analytics: The project involved analyzing geolocation data using Pandas in Python. The data was obtained from GPS devices and contained latitude, longitude, and timestamps. The objective was to identify patterns and trends in the data to gain insights into the behavior of individuals and groups. Data cleaning techniques were applied to remove outliers and missing values. The cleaned data was then grouped and aggregated to calculate metrics such as distance traveled, speed, and duration. Visualization techniques such as heat maps and scatter plots were used to represent the data visually.
cross-datasource-entity-matching: The project leverages Deep Learning algorithms to perform Record Linkage, or entity matching, by comparing and matching data from separate datasources. By utilizing Deep Learning, the project can accurately identify and link similar entities, streamlining data integration and reducing errors.
DevOps
supabase-python: This project provides a lightweight Python interface for working with Supabase in backend workflows, enabling developers to programmatically interact with Supabase services such as the PostgreSQL database, authentication, and storage from Python applications. It is designed for engineers who want to integrate Supabase into Python-based systems, scripts, or backend services without relying on JavaScript tooling, offering a clean and minimal API for performing common operations like querying tables, inserting and updating records, and managing data pipelines.
aws-localstack-stream-processing: This project implements a scalable, event-driven architecture for secure transaction signing using AWS LocalStack for local emulation. It ingests high-throughput unstructured data into Kinesis, persists raw inputs to S3 for replay, and routes records through an intermediate batching stream that triggers a Lambda function. The Lambda retrieves RSA private key ARNs from Aurora Serverless, signs the batched data, and stores signed payloads in a separate S3 bucket. Built with CDK and Docker Compose, the system ensures reliable, exactly-once processing with optimized Lambda performance and modular RSA key management via AWS Secrets Manager.
aws-sagemaker-cdk: This project automates the deployment and management of multiple machine learning models using AWS services like SageMaker, Lambda, API Gateway, and EventBridge, ensuring seamless integration and scalable real-time inference.
gcp-kubernetes: This project involved setting up a Kubernetes cluster on Google Cloud Platform using Google Cloud Deployment Manager, automating the creation and management of GCP resources. I developed YAML and Jinja templates to efficiently deploy a multi-node Kubernetes cluster, enhancing scalability and availability.
aws-django-ansible: The project utilizes Ansible in a Docker container to implement a Django application. It provides flexibility by connecting to AWS EC2 instances, allowing seamless deployment and management of the application in both local and cloud environments.
grpc-python: This project implements high-performance gRPC services in Python, enabling efficient microservices communication and streaming. It provides a foundation for building scalable, type-safe APIs and real-time data exchange between services using protocol buffers.
terraform-aws-django: The project aims to automate the deployment of a Django application using Terraform. It provisions an EC2 instance in a public subnet, installs necessary dependencies, and runs the application using Gunicorn.
aws-django-kubernetes: The project utilized Django as the primary technology stack for building a web application that was deployed on AWS Kubernetes. The application made use of Kubernetes for container orchestration and management, while Django provided a framework for building the RESTful APIs that the application relied on. The system also integrated with various AWS services such as S3 for file storage and RDS for database management.
aws-networking-elastic-beanstalk-automation: The project utilized AWS CDK to create multiple Cloud Formation stacks for deploying various AWS services. These services included an AWS network, an RDS instance, an Elasticache cluster, an OpenSearch service, and an Elastic Beanstalk instance. AWS CDK allowed for the creation of infrastructure as code, providing a more streamlined and consistent approach to deployment.
supervisor-python: The project is a Python script managed by Supervisord, creating a daemonized service that runs continuously on Linux and automatically restarts if crashed, providing robust and reliable system operation.
python-splunk-cli: This project develops Python integration with Splunk for log analysis and monitoring, enabling efficient log processing and visualization. It offers a CLI and programmatic access to query logs, run searches, and automate operational insights from Splunk data.
filesystem-tools: This project engineers file system management tools with AWS S3 integration, enabling efficient cloud storage operations and automation. It supports uploads, downloads, sync, and scripting for bulk and recurring storage tasks on Linux and cloud environments.
development-tools: This project creates comprehensive development tools for Python, Android, TypeScript, Django, Git, and GPT integration. It bundles scripts and utilities to streamline local development, version control, and AI-assisted workflows across multiple stacks.
python-jira-cli: This project develops Python integration with JIRA, enabling automated issue tracking and project management. It provides a CLI and API helpers to create, update, and query issues and projects programmatically from scripts and toolchains.
web-to-pdf: This project engineers web scraping tools using Python and Beautiful Soup, enabling efficient content extraction and PDF conversion. It fetches web pages, parses structure and text, and generates PDFs for offline reading or archival.
python-web-crawler: The project involved using Python and the asyncio library to create a web crawler that could efficiently scrape and process data from multiple websites simultaneously. The crawler was designed to handle large volumes of data by using asyncio's event loop to manage concurrent requests and minimize blocking I/O operations. The project also made use of other Python libraries such as requests, BeautifulSoup, and pandas to extract, process, and analyze the scraped data.
Blockchain
bitcoin-wallet-generator: This project provides code for generating Bitcoin wallets that can store BTC without relying on third-party services like Blue Wallet or Electrum. It demonstrates key generation, address derivation, and secure storage of keys for self-custody of Bitcoin.
real-estate-solidity-contract: This project develops secure and auditable real estate smart contracts in Solidity, implementing Merkle trees for efficient property verification on-chain. It supports proof of ownership, transfers, and compliance checks in a decentralized real estate workflow.
solidity-upgradeable-contract: This project is a Solidity-based upgradeable smart contract system leveraging OpenZeppelin's upgradeable libraries to provide secure and flexible access control, signature verification, and contract management. It includes a Manager contract that handles role-based access control, pausability, upgradeability with state migration, and integration with an external Verifier contract for validating user signatures. Built with Foundry for testing and deployment, the system ensures security through strict role enforcement, robust error handling, and seamless upgrade mechanisms.
rust-alloy: This project is a Dockerized Rust API that leverages Tokio, Warp, Alloy, Foundry, and Grafana to interact with Ethereum nodes, providing balance queries and real-time monitoring. It integrates Anvil for local Ethereum development, OpenTelemetry for tracing, and Prometheus + Grafana for monitoring, making it a robust solution for blockchain-based applications. The API is built with Warp for high-performance async HTTP handling and supports structured logging, CORS, and OpenTelemetry tracing. With a simple Docker Compose setup, it allows seamless deployment and local development, ensuring a production-ready Ethereum API environment.
zk-trust: This project, titled zk-trust, leverages Zero-Knowledge Proofs to enhance security in the DeFi ecosystem by verifying the attributes of ERC20 tokens before they are listed on platforms. By implementing a robust validation mechanism off-chain and confirming the authenticity on-chain via a Solidity smart contract, this system helps prevent fraud similar to the recent Ionic Money Hack, ensuring only legitimate tokens are used within the platform.
zk-proof: This project demonstrates a zero-knowledge proof system using RiscZero's zkVM. It compiles a guest program located in the ./methods/guest directory into an ELF binary, which is then executed by a host Rust application that also runs a Warp server. The server exposes endpoints to remotely trigger zkVM executions, allowing users to submit inputs, obtain the computed result along with a cryptographic proof of execution, and ultimately validate that proof on-chain. The entire process is containerized using Docker, ensuring a reproducible and isolated environment for development and deployment.
anvil-of-fury: This project involved the development of an Ethereum-based application using the Web3.js library, which provided an engaging platform to interact with the blockchain. My role encompassed setting up a local development environment using Anvil, crafting scripts for sending transactions, and managing wallet balances. I successfully implemented functionality to handle cryptocurrency transactions dynamically by connecting to and interacting with a simulated Ethereum network. This experience enhanced my understanding of blockchain technology, Ethereum smart contracts, and the intricacies of transaction fee mechanisms.
ethereum-solidity-contract: The project involved developing a smart contract on the Ethereum network using Solidity programming language. The contract was designed to facilitate a decentralized voting system that could be implemented across various organizations. The contract was created to ensure transparency and security in the voting process while also reducing the potential for fraud. Additionally, the project involved testing the smart contract using the Remix IDE and deploying it to the Ethereum network using tools like Ganache and Truffle. The smart contract was deployed on a private network and was also tested using the Ropsten test network.
django-multi-blockchain: The project involves building a cross-chain environment where users can log in to a Django SSO (Single Sign-On) server and access other Django servers connected to the Solana, Ethereum, and Polygon networks. The SSO server is responsible for authentication and authorization, while the other servers are responsible for interacting with their respective networks.
solana-token-rust: The project involved creating a Solana NFT using CandyMachine, a tool that allows creators to mint NFTs on the Solana blockchain, and Rust Programs. Rust was used to write the smart contract that governs the creation, distribution, and sale of the NFTs. The NFTs were stored on the Solana blockchain, making them easily transferable and secure.
rust-ecopark: This project builds a high-performance database application in Rust, implementing efficient MySQL queries and Docker containerization. It offers a fast, reliable backend for data access and is designed for deployment in containerized and cloud environments.
Backend
django-admin-react: This project is a drop-in React single-page admin for any Django 5+ project, modernising Django's classic hypertext admin without requiring any frontend code from the developer. The package is metadata-driven: it learns your models, fields, and permissions at runtime from a registry endpoint, and renders virtualised tables, mobile-friendly layouts, inline editing, filters, search, bulk actions, autocomplete pickers, and inlines directly from your existing ModelAdmin classes. Permissions, querysets, fieldsets, and read-only rules are honoured verbatim, so a new ModelAdmin only requires a page refresh — no rebuild or codegen.
django-admin-rest-api: This project exposes every ModelAdmin already registered on the Django admin site through a JSON REST API, without introducing a parallel permission system, a parallel form layer, or any feature the Django admin itself does not have. Authentication, authorization, field validation, actions, search, filters, and audit logging are all delegated to the existing Django setup: requests run through the same ModelForm, the same has_view/add/change/delete_permission checks, and Django's own LogEntry history. It is the stable wire surface that powers django-admin-react and django-admin-mcp-api.
django-admin-mcp-api: This project is an MCP (Model Context Protocol) adapter for the Django admin that lets AI agents read rows, retrieve, create, update, and delete records, run admin actions, and use autocomplete through the standard MCP protocol. It is a thin wire-protocol layer sitting on top of django-admin-rest-api — the same authentication, the same permissions, no extra validation, and no new business logic — so it safely exposes the Django admin's existing capabilities to LLMs.
geometry.martincastroalvarez.com: This project is a computational geometry application implementing art gallery algorithms, convex decomposition, and guard placement from first principles. It includes a React web app for visualization, a Python API for computations, and AWS CDK for deployment and hosting.
python-fastapi: This project engineers a high-performance REST API using FastAPI, implementing async operations and automatic OpenAPI documentation. It is designed for low-latency, scalable backends with built-in validation, dependency injection, and interactive API docs.
geo-django: The project is a geospatial application that leverages GeoDjango and PostGIS to create and manage multiple points, lines, and polygons. It calculates distances between these objects and performs various operations using them to support geospatial analysis and visualization.
hexagonal-spring-boot: The project utilizes Hexagonal Architecture in Java Spring Boot for e-commerce management with a React and Tailwind frontend. It features domain models, service interfaces, and custom exceptions to streamline operations, supported by comprehensive unit tests. Key functionalities, including user and product management, are demonstrated in interactive demos. The architecture promotes modularity and ease of maintenance, ensuring adaptability and scalability through well-defined web and database API adapters.
node-typescript-pdf-renderer: The project involved utilizing NodeJS and TypeScript to dynamically render PDFs based on user input. NodeJS provided a reliable and efficient backend framework for handling data processing and file generation, while TypeScript was used to ensure type safety and code consistency. The project also made use of various PDF generation libraries such as pdfkit and Puppeteer to facilitate PDF rendering.
ai-syntax-compiler: This project develops a custom programming language compiler for data scientists, implementing lexical analysis and parsing using Bison and Lex. It defines a small DSL and toolchain for expressing data and analytics operations with a dedicated syntax and runtime.
automata-python: This project implements various automata algorithms in Python, enabling efficient pattern matching and language processing. It covers finite automata, regular expressions, and related constructs used in compilers, parsers, and text processing.
java-spring-boot: The project utilized Java Springboot as the main technology stack for building a web application. Springboot provided a framework for creating RESTful APIs, which were used to handle user requests and data retrieval from a MySQL database. The application also implemented security features such as user authentication and authorization using Spring Security. Overall, Springboot proved to be a reliable and efficient tool for building a scalable web application.
data-structures-java: This project implements efficient data structures in Java, focusing on performance optimization and algorithm complexity. It provides well-tested implementations of trees, heaps, graphs, and other structures with clear APIs and complexity guarantees.
django-data-analytics: This project builds a comprehensive data analytics platform using Django, implementing PnL, LTV, and retention analysis. It offers dashboards, reports, and APIs for business and product metrics with a Django-backed storage and computation layer.
go-lang-app: This project develops high-performance applications using Go, implementing concurrent processing and efficient resource utilization. It leverages goroutines and channels for concurrency and is suited for services requiring low latency and high throughput.
django-cms: This project is a Content Management System (CMS) built using the Django web framework. The CMS will enable users to create, edit, and publish digital content, such as articles, blog posts, and multimedia files, using an intuitive web-based interface. The CMS will also include features such as user authentication, content versioning, and search functionality.
flask-mongodb-celery-messaging-api: This project involved the implementation of a chat server using Redis, Celery, MongoDB, and Flask. Redis was used for message queueing and socket management, while Celery was used for asynchronous task processing. MongoDB was used to store user information and chat history, and Flask was used to provide the web interface. The project also involved implementing a RESTful API for mobile client communication.
python-s3-media-server: This project develops a file server using Flask and PIL, implementing efficient image processing and S3 storage integration. It serves and transforms images on demand and persists assets to AWS S3 for scalable media hosting.
python-chat-server-sockets: This project engineers a real-time chat server using Python sockets, enabling efficient network communication and message handling. It supports multiple concurrent clients and demonstrates low-level TCP socket programming and protocol design.
python-google-spreadsheets: This project develops Python integration with Google Spreadsheets, enabling automated data processing and analysis. It uses the Google Sheets API to read, write, and transform spreadsheet data from scripts and pipelines.
software-patterns: This project implements various software design patterns in Python, demonstrating best practices for maintainable and scalable code. It includes examples of creational, structural, and behavioral patterns with clear use cases and trade-offs.
Frontend
react-pnpm-workspaces: This project is a monorepo template for sharing UI components between React web and React Native mobile apps using pnpm workspaces. It demonstrates platform-specific implementations with Vite, Expo, and TypeScript in a scalable architecture for cross-platform development.
microfrontends: The project is centered on implementing a distributed frontend architecture for medium and large companies. It aims to enhance scalability and maintainability in web development by modularizing the frontend, thus facilitating smoother collaboration and more agile processes in complex, large-scale applications.
nextjs-app: This project builds a modern web application using Next.js, implementing server-side rendering and optimized performance. It leverages file-based routing, API routes, and static or dynamic rendering for fast, SEO-friendly web experiences.
vuejs-app: This project develops a responsive web application using Vue.js and TypeScript, implementing component-based architecture. It uses the Composition API and type-safe patterns for maintainable, reactive user interfaces and single-page applications.
svelte-app: This project engineers a high-performance web application using Svelte, implementing reactive programming and efficient DOM updates. It compiles to minimal JavaScript and uses reactive declarations for fast, lean front-end experiences without a virtual DOM.
react-typescript-app: This project builds a type-safe React application using TypeScript, implementing modern frontend development practices. It combines React components with strict typing, hooks, and tooling for reliable and maintainable user interfaces.
react-firebase-oauth: The project is a React application that uses Firebase and Google OAuth 2.0 authentication for secure user access to protected resources. It includes custom login and registration forms, and utilizes modern web technologies such as React, JavaScript, and CSS. Integration with third-party libraries and services enhances the overall reliability and robustness of the application.
flexbox-project: The project is a web development endeavor aimed at implementing flexbox, a powerful layout system used in modern CSS, with a focus on creating flexible and responsive designs. Through this project, developers will gain an understanding of the different properties and techniques that can be utilized to achieve custom layouts for their web pages. By leveraging flexbox, users will be able to create dynamic and adaptive interfaces that adjust to the size and orientation of various devices.
typescript-map-reduce: This project engineers efficient data processing using TypeScript, implementing map-reduce patterns for large datasets. It demonstrates how to partition work, aggregate results, and handle streaming or batch data in a type-safe Node or browser environment.
typescript-mongodb-nestjs-mvc: This project builds a full-stack MVC application using TypeScript, MongoDB, and NestJS, implementing clean architecture principles. It provides a structured backend with dependency injection, modules, and MongoDB integration for scalable API and data layers.
typescript-classes: This project implements object-oriented programming patterns in TypeScript, demonstrating advanced class design and inheritance. It covers encapsulation, abstraction, and type-safe OOP constructs for structuring front-end or Node.js applications.
dam: Full-stack digital asset management with a React 19 and TypeScript frontend (Vite, Tailwind CSS, React Router, Formik, Yup) and a Firebase backend: Auth, Firestore, Cloud Storage, and Node.js Cloud Functions. Local development runs the Firebase Emulator Suite in Docker for isolated Auth, Firestore, Storage, and Functions.
Testing
cypress-tests: This project showcases the integration of Cypress tests within a web development environment, emphasizing the crucial role of automated testing in building robust, error-free applications. By leveraging Cypress, an advanced end-to-end testing framework, the project aims to demonstrate best practices in test automation for both small and large-scale web projects.
flask-application: This project engineers a Flask REST API with 100% unit test coverage, implementing robust testing practices and continuous integration. It serves as a reference for building well-tested Python APIs and integrating them into CI/CD pipelines.
javascript-selenium-web-driver: This project builds an automated testing framework using Selenium WebDriver, enabling comprehensive browser-based testing. It automates user flows, assertions, and cross-browser checks for reliable end-to-end and regression testing of web applications.
Mobile
python-android-manager: This project develops a web API for remote Android device emulator management, enabling efficient mobile testing and automation. It allows teams to control emulators, install builds, and run tests from CI or scripts for scalable mobile QA workflows.
unlam-android-app: This project engineers a native Android calendar application, implementing efficient data management and user interface. It provides event creation, editing, and scheduling with a native UI and local or synced storage for personal or educational use.
Quantum Computing
quantum-algorithms-java: The project involved using Java to implement quantum algorithms for various applications. Java was chosen for its versatility, and the quantum algorithms were implemented using the Qiskit library. The project also utilized various quantum simulators to test the algorithms, including the IBM Quantum Experience platform. Overall, the use of Java proved to be effective in implementing complex quantum algorithms, and the project provided valuable insights into the potential applications of quantum computing.
assembly-logisim-circuits: This project develops digital logic circuits using Logisim, implementing assembly language programming and circuit simulation. It demonstrates how to design and simulate low-level hardware and instruction sets for educational or prototyping purposes.
Books




























































